ps. 本文翻译自:Inside The Python Virtual Machine,文中有许多词不达意的地方,为个人学习翻译。
1、Introduction
python这门语言已经存在有一段时间了。Guido Van Rossum 于 1989 年开始对第一版进行开发,此后 python 成为最受欢迎的语言之一,被广泛用于图形界面,财务和数据分析应用中。
本文旨在深入介绍 Python 解释器,并提供有关 python 程序如何执行的概念性概述。在撰写本文时, CPython 是 Python 最受欢迎的实现,并被视为标准。
python 程序的执行一般分为以下两个或三个主要阶段,区分方式具体取决于解释器的调用方式。在本文中,下面这些包含在不同的部分中:
Initialization:这涉及到 python 进程所需的各种数据结构的建立。这可能仅在通过解释器 shell 非交互地执行程序时才会有这一步骤。
Compiling:这涉及诸如解析源代码以构建语法树 (syntax trees) ,创建抽象语法树 (abstract syntax trees) ,构建符号表 (symbol tables) 以及生成代码对象 (code objects) 之类的活动。
Interpreting:这涉及在某些上下文中实际执行生成的代码对象。
从源代码生成解析树和抽象语法树的过程与语言无关,因此适用于其他语言的相同方法也适用于 Python ;所以这里没有涉及这个方面的主题。另一方面,从“抽象语法树“构建符号表和代码对象的过程是编译阶段中比较有趣的部分,该过程或多或少地会以 python 特定的方式处理。本文还介绍了编译后的代码对象以及该过程中使用的所有数据结构。这将涉及包括但不限于构建符号表和生成代码对象,Python 对象, frame 对象,代码对象,函数对象,python 操作码,解释器循环,生成器和用户定义类的过程等。
2、The View From 30,000ft
本章从高层次上介绍了解释器如何执行 python 程序。在随后的章节中,我们将放大难题的各个部分,并提供对这些内容更加详细的描述。无论 python 程序的复杂程度如何,这个过程都是相同的。 Yaniv Aknin 在 Python Internal series 这篇文章中对这个过程的提供了精彩解释。
给定一个 python 模块,如:test.py,可以将该模块作为参数传递给 python 解释器程序,从而可以在命令行中执行该模块,例如:$ python test.py。这只是调用 python 可执行文件的方式之一;我们还可以启动交互式解释器,把字符串当做代码执行等等,但是其他这些执行方法对我们而言并不重要。当在命令行上把模块作为参数传递给可执行部分 (executable) 时,图 2.1 阐述了所提供模块实际执行中涉及的各种活动的流程。
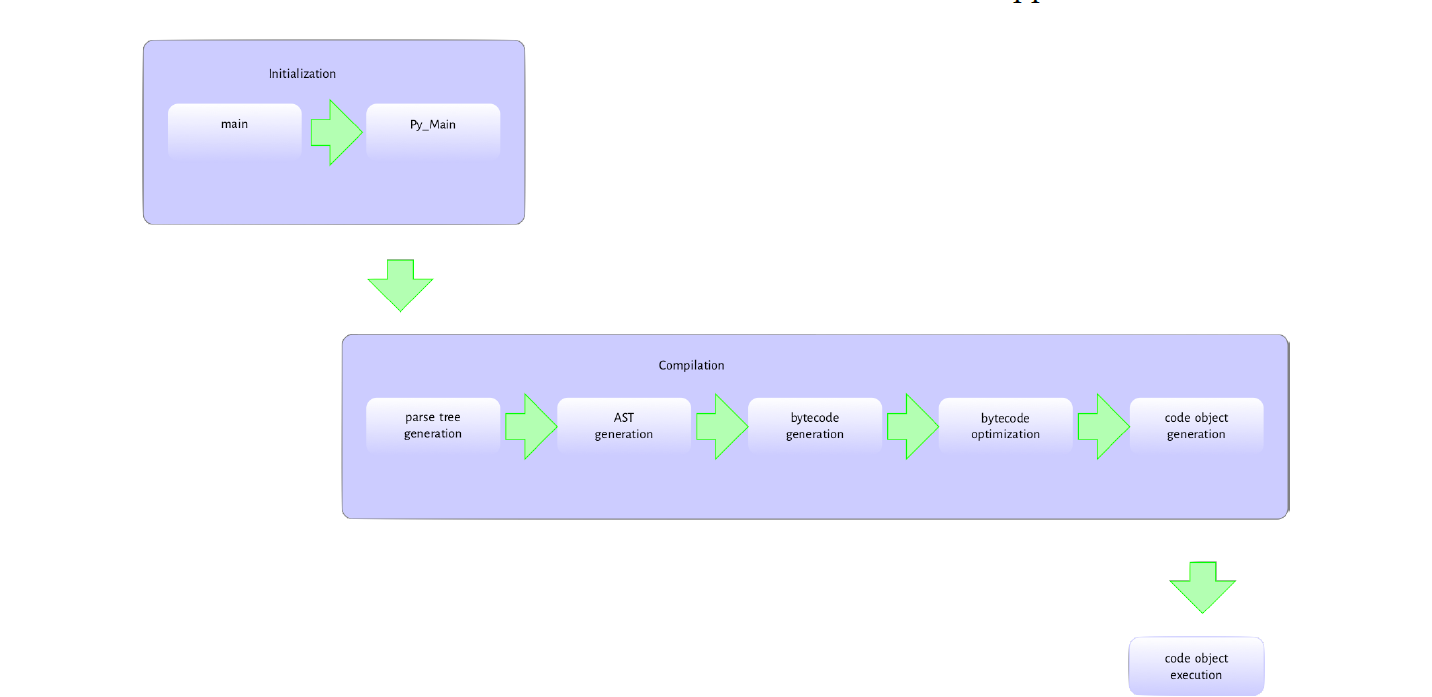
python 可执行文件是 C 程序,就像其他任何 C 的程序 (例如 linux 内核或 C 中的 hello world 程序) 一样,因此在调用 python 可执行文件的时候,发生的过程几乎相同。总而言之,python 可执行程序只是另一个运行你自己的程序的程序。 C 与汇编语言或者 llvm 之间的关系和上述的关系相同。
一旦以模块名称作为参数调用 python 可执行程序,就会启动基于可执行文件运行平台的标准初始化程序,C 运行时执行所有初始化方法:加载库,检查或设置环境变量,然后像任何其他的 C 程序一样运行 python 可执行程序的 main 方法。
python 可执行程序的 main 程序位于 ./Programs/python.c 文件中,它处理一些初始化操作,例如把传递给模块的程序命令行参数制作一个副本。然后,main 函数调用位于 ./Modules/main.c 中的 Py_Main 函数,该函数处理解释器程序初始化的过程:解析命令行参数和设置程序标记,读取环境变量,运行钩子,执行哈希随机化等等。在初始化过程中,会从 pylifecycle.c 调用 Py_Initialize 方法;它对解释器和线程状态的数据结构进行初始化操作,这是两个非常重要的数据结构。查看解释器和线程状态的数据结构定义可以为这些数据结构的方法提供上下文。解释器和线程状态只是具有指向一些字段的指针的结构体,这些字段包含程序执行所需的信息。
list 2.1 中提供了解释器状态 typedef 结构体 (这并不是完全正确的,因为假定这是由 C 语言定义的类型) 。
Listing 2.1:解释器状态的数据结构
1 | typedef struct _is { |
任何使用 Python 语言的时间足够长的人都可以识别此结构中提到的一些字段 (sysdict,builtins 和 codec)*。
*next字段是对另一个解释器实例的引用,因为同一进程中可以存在多个 python 解释器。*tstate_head字段指向执行的主线程:如果 python 程序是多线程的,则解释器由程序创建的所有线程共享,接下来就会讨论线程状态的结构。modules,modules_by_index,sysdict, 和importlib字段意义都是显而易见的,它们都被定义为 PyObject 的实例,在虚拟机中,PyObject是所有 python 对象的根类型。随后的章节有更多关于 Python 对象的详情。- 与
codec*相关的字段中包含了关于加载编码和位置的相关帮助信息,这些对于解码字节非常重要。
程序的执行必须在线程内进行。线程状态结构体中包含了线程执行 python 某些代码对象所需的所有信息,list 2.2 中展示了线程数据结构的一部分。
Listing 2.2: A cross-section of the thread state data structure
1 | typedef struct _ts { |
解释器和线程状态数据结构将在后续章节中详细讨论。初始化过程还设置了导入机制以及基本的 stdio。一旦完成所有初始化后,Py_Main 函数将调用也位于 main.c 模块中的 run_file 函数。
接下来是一系列函数调用:PyRun_AnyFileExFlags -> PyRun_SimpleFileExFlags -> PyRun_FileExFlags -> PyParser_ASTFromFileObject,这些调用组成了 PyParser_ASTFromFileObject 函数。PyRun_SimpleFileExFlags 函数调用创建了 __main__ 命名空间,并在其中执行文件的内容。
它还会检查文件的 pyc 版本是否存在:pyc 文件只是一个包含正在执行文件的编译版本的文件。如果文件有 pyc 版本,则将尝试以二进制方式读取,然后运行。在这种情况下,如果没有 pyc 文件,则会调用 PyRun_FileExFlags 方法等等。
PyParser_ASTFromFileObject 函数调用 PyParser_ParseFileObject,后者读取模块内容并从中构建一个解析树(parse tree)。然后创建好的解析树会被传递到 PyParser_ASTFromNodeObject 之中,再之后 PyParser_ASTFromNodeObject 继续从该解析树创建抽象语法树 (abstract syntax tree) 。
然后将生成的 AST 会传递给 run_mod 函数。该函数调用 PyAST_CompileObject 函数,它会从 AST 创建代码对象。请注意,在调用 PyAST_CompileObject 的过程中生成的字节码是通过一个简单的 peephole 优化器传递的,该优化器在创建代码对象之前对生成的字节码进行低悬挂 (low hanging) 优化。
然后 run_mod 函数从代码对象上的 ceval.c 文件中调用 PyEval_EvalCode。这会导致另外的一系列函数调用:PyEval_EvalCode -> PyEval_EvalCode -> _PyEval_EvalCodeWithName -> _PyEval_EvalFrameEx。代码对象以某种形式作为参数传递给这些函数。
_PyEval_EvalFrameEx 是处理代码对象执行的常规解释器循环 (interpreter loop) 。但是,它不仅仅把代码对象作为参数来调用,具有引用代码对象字段的 frame 对象也是其参数之一。该 frame 对象提供了代码对象执行的上下文。这里发生的事情可以简单描述为:解释器循环从指令数组中持续不断的读取指令计数器然后指向的下一条指令。然后执行该指令:在进程中从 value stack 中添加或删除对象,直到数组中不再有需要执行的指令或发生破坏该循环的异常事件为止。
Python 提供了一组函数,可用于探索实际的代码对象。例如,可以将一个简单程序编译为一个代码对象,然后将其反汇编以获取由 python 虚拟机执行的操作码,如 list 2.3 所示。
Listing 2.3: Disassembling a python function
1 | def square(x): |
./Include/opcodes.h 头文件中包含 python 虚拟机的所有指令/操作码的完整列表。从概念上讲,这些操作码非常简单。以 list 2.3 中的操作码为例,其中包含四个指令:
LOAD_FAST 将其参数的值 (即 x) 加载到执行 (值) 堆栈 (evaluation stack) 上。 python 虚拟机是基于堆栈的虚拟机,因此这意味着从堆栈中获取操作码进行执行的值,会被放回到堆栈上,以供其他操作码进一步使用。
然后 BINARY_MULTIPLY 操作码从值堆栈中弹出两个元素,对两个值都执行二进制乘法,并将二进制乘法的结果放回到值堆栈上。
RETURN VALUE 指令从堆栈中弹出一个值,将对象的返回值设置为该值,然后退出解释器循环。
从 list 2.3 的反汇编中可以明显看出,这种对解释器循环操作的简单解释遗漏了许多细节,这些细节将在后续章节中进行讨论。其中可能会包括一些悬而未决的问题。
在执行完所有指令之后,Py_Main 函数将继续执行,但是这次是围绕它开始清理的过程。就像在解释器启动期间调用 Py_Initialize 进行初始化一样,清理过程会调用 Py_FinalizeEx 进行清理工作。此清理过程包括等待线程退出,调用所有退出钩子以及释放由解释器分配的仍在使用的所有内存。
上面的描述是 python executable 执行 python 程序所经过的过程的高级 (high-level) 描述。正如前面所说的那样,有许多细节尚待回答。在接下来的章节中,我们将深入探讨涉及的每个阶段,并尝试提供每个阶段的细节。我们将从下一章中的编译过程的描述入手。
3、Compiling Python Source Code
一般来说,尽管 python 不被认为是一种编译语言,但实际上它就是一种编译型语言。在编译期间,一些 python 源代码会被转换为虚拟机可执行的字节码。但是,在 python 中这个编译的过程非常的简单,它并不涉及太多复杂的步骤。一个 python 程序的编译过程会涉及以下步骤:
- 将 python 源代码解析为解析树。
- 将解析树转换为抽象语法树 (AST) 。
- 生成符号表。
- 从 AST 生成代码对象。此步骤包括:
1. 将 AST 转换为控制流程图。- 从控制流程图中生成代码对象。
将源代码解析为解析树并将该解析树转换为 AST 是一个标准过程,而 python 并没有引入任何复杂而细微区别,因此本章的重点是将 AST 转换为控制流图以及从控制流程图中生成代码对象。如果你对解析树和 AST 生成感兴趣,《dragon book》会提供一些对这两个主题的更加深入的解释。
3.1 From Source To Parse Tree
python 的解析器是 LL(1) 解析器,它是基于《Dragon book》中对此类解析器的描述。Grammar/Grammar模块包含了对于 python 来说的 Extended Backus-Naur Form(EBNF)语法规范。list 3.0 中显示了这个规范大致情况。
Listing 3.0: A cross section of the Python BNF Grammar
1 | stmt: simple_stmt | compound_stmt |
当在命令行上执行一个传递给解释器的模块时,会调用 PyParser_ParseFileObject 函数解析这个模块。该函数调用标记 (tokenization) 函数 PyTokenizer_FromFile,并将模块的文件名作为参数传递。标记函数将模块的内容分解为合法的 python tokens,或者在发现非法值时引发异常。
3.2 Python tokens
Python 源代码由 tokens 组成。例如,return 是关键字 token,2 是数字 token 等等。解析 python 源代码时的第一个任务是标记化源文件,将其分解为 token。 Python 有许多类型的 token,如下所示。
- 标识符 (identifiers):这些名称是程序员定义的,包括函数名称,变量名称,类名称等。它们必须符合 python 文档中指定的标识符规则。
- 运算符 (operators):这些是特殊符号,例如 +,*,它们对数据进行运算并产生结果。
- 分隔符 (delimioters):这组符号用于对表达式进行分组,提供标点符号以及赋值。此类别中的示例包括(,),{,},=,*= 等。
- 字面量 (literals):这些是为某些类型提供定值的符号。其中有字符串和字节,例如 “Fred”,b“Fred” 和数值,包括整型 (例如2),浮点型 (例如1e100) 和虚数类型 (例如10j)。
- 注释 (comments):以哈希符号开头的字符串。注释 token 始终在物理行结尾处结束。
- NEWLINE:这是一个特殊 token,表示逻辑行的结尾。
- INDENT 和 DEDENT:这些 token 用于表示复合语句分组的缩进级别。
一组由 NEWLINE token 划定的 tokens 组成一条逻辑行,因此我们可以说 python 程序由一系列逻辑行组成,每条逻辑行都由 NEWLINE token 划定。这些逻辑行映射到 python 的语句。这些逻辑行均由多个物理行组成,每个物理行以一个行尾序列终止 (an end-of-line sequence)。在 python 中,大多数情况下逻辑行都会映射到物理行,因此逻辑行由行尾字符分隔。如图 3.0 所示,复合语句可以跨越多个物理行。当表达式位于括号,方括号或花括号中时,逻辑行可以隐式连接在一起,也可以使用反斜杠字符将逻辑行显式连接在一起。缩进在 python 语句中也起着核心作用。因此,python 语法中的一行是:simple_stmt | NEWLINE INDENT stmt + DEDENT,因此 python tokenizer 的主要任务之一就是生成 indent 和 dedent tokens,这些 tokens 将会加入到解析树中。tokenizer 使用堆栈来跟踪缩进,并且使用 list 3.1 中的算法来生成 INDENT 和 DEDENT tokens。
Listing 3.1: Python indentation algorithm for generting INDENT and DEDENT tokens
使用 0 初始化缩进堆栈。
对于考虑了行连接的每个逻辑行:
A. 如果当前行的缩进大于堆栈顶部的缩进
1.将当前行的缩进添加到堆栈顶部。
2.生成一个 INDENT token。
B. 如果当前行的缩进小于堆栈顶部的缩进
1.如果堆栈上没有与当前行匹配的缩进级别,则报错。
2.对于每个在堆栈顶部且不等于当前行的缩进。
a. 从堆栈顶部删除该值。
b.生成一个 DEDENT token。
C. tokenizer 当前行。
对于堆栈上除 0 以外的每个缩进,生成一个 DEDENT token。
Parser/parsetok.c 模块中的 PyTokenizer_FromFile 函数从左到右,从上到下扫描 python 源文件,对文件内容进行 tokenize 。除终止符外的空白字符也可当做分隔字符 (delimit token),但这不是必需的。在有歧义的地方 (例如 2 + 2),一个 token 由从右到左读取的最长字符串构成一个合法的 token。在此示例中,tokens 是字面量 2,运算符 + 和字面量 2。
将从 tokenizer 生成的 tokens 传递到解析器,解析器尝试根据 list 3.0 中指定 python 语法子集构建解析树。当解析器遇到违反语法的 token 时,将引发 SyntaxError 这个异常。从解析器中输出的是一个解析树。python 的parser 模块对一块 python 代码的解析树提供了有限的访问,list 3.2 展示了使用这些得到了一个完整的解析树的示例。
Listing 3.2: Using the parser module to obtain the parse tree of python code
1 | >>>code_str = """def hello_world(): |
只要提供的源代码在语法上是正确的,上面 list 3.2 中的 parser.suite(source) 调用就会从提供的源代码中返回一个 parse tree(ST) 对象,即 parse tree 的 python 中间表示形式。parser.st2list 调用返回以 python 列表形式表示的真正的 parse tree。列表中的第一项是整数,它标识 python 语法中的生产规则。
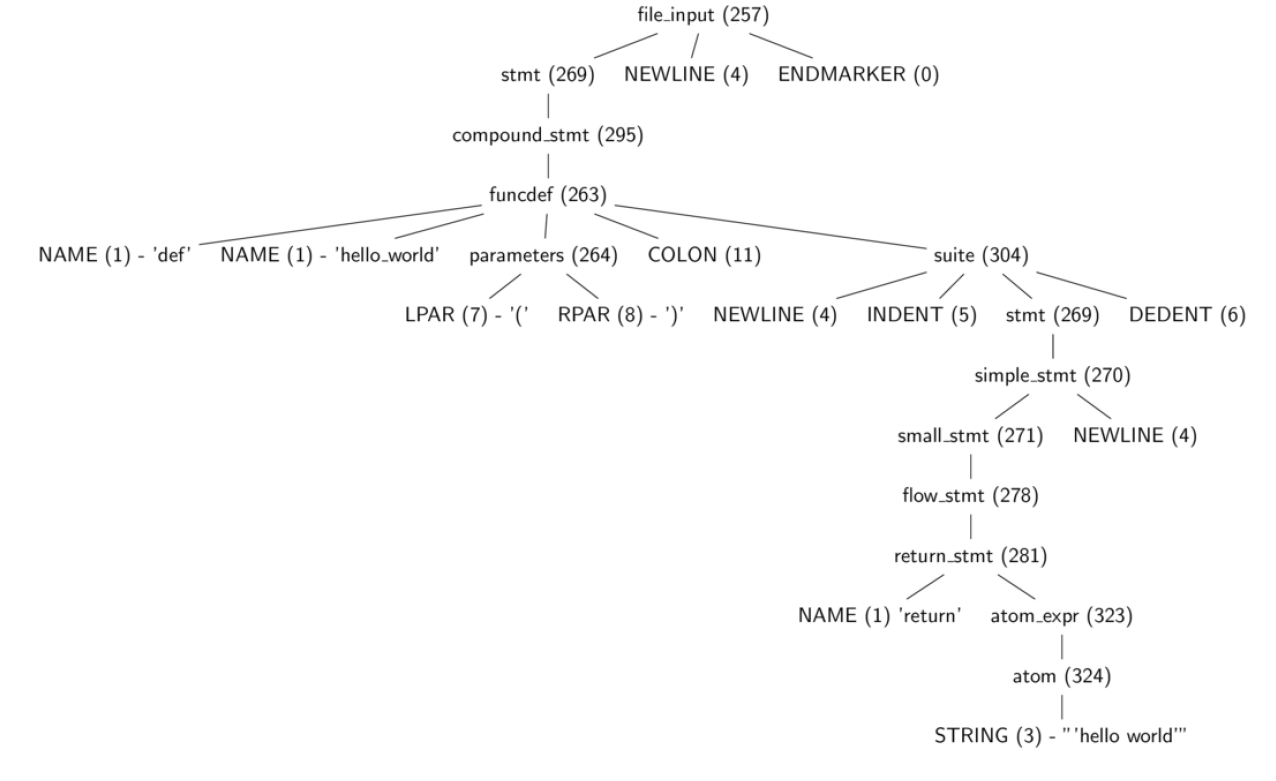
Figure 3.0: A parse tree for listing 3.2 (function that returns the ‘hello world’ string)
图 3.0 是一个树形图,显示了 list 3.2 中的相同 parse tree,其中一些 tokens 被去除,并且可以看到部分整数值表示的语法部分。这些生成规则均在 Include/token.h (terminals) 和 Include/graminit.h (terminals) 头文件中指定。
在 CPython 虚拟机中,树这种数据结构用于表示 parse tree。每个生成规则都是树数据结构上的一个节点。list 3.3 中的 Include/node.h 显示了这个节点数据结构。
Listing 3.3: The node data structure used in the python virtual machine
1 | typedef struct _node { |
在遍历 parse tree 时,我们可以查询节点的类型,子节点 (如果有的话),导致给定节点创建的行号等等。在 Include/node.h 文件中也定义了与 parse tree 节点进行交互的宏。
3.3 From Parse Tree To Abstract Syntax Tree
编译过程的下一个阶段是将 python 解析树 (parse tree) 转换为抽象语法树 (AST) 。抽象语法树是独立于python 语法的代码表示形式。例如,解析树包含如图 3.0 所示的冒号节点 (colon node) ,因为它是一种语法结构,但 AST 将不包含如 list 3.4 所示的语法结构。
Listing 3.4: Using the ast module to manipulate the AST of python source code
1 | import ast |
在文件 Parser/Python.asdl 文件中可以找到各种 Python 的 AST 节点的定义。 AST 中的大多数定义都与特定来源的结构相对应,例如 if 语句或属性查找。与 python 解释器捆绑在一起的 ast 模块为我们提供了操作 python AST 的能力。诸如 codegen 之类的工具可以在 python 中使用 AST 进行表示,并输出相应的 python 源代码。在 CPython 的实现中,AST 节点由 C 的结构表示,正如在 Include/Python-ast.h 中所定义的一样。这些结构实际上是由 python 代码生成的;Parser/asdl_c.py 模块会根据 AST asdl 定义生成此文件。例如,list 3.5 中展示了部分声明节点(statement node)的定义。
Listing 3.5: A cross-section of an AST statement node data structure
1 | struct _stmt { |
list 3.5 中的联合类型 (union) 是 C 中的类型,它可以表示联合中列出的任何类型。 Python/ast.c 模块中的 PyAST_FromNode 函数处理从给定的解析树生成 AST 的过程。生成 AST 之后,就是从 AST 中生成字节码了。
3.4 Building The Symbol Table
生成 AST 后,该过程的下一步是生成符号表 (symbol table) 。就像名字所表达的一样,符号表是代码块中名称的集合,并且这些名称在上下文中被使用了。建立符号表的过程涉及到分析代码块中包含的名称,并为这些名称分配正确的作用域。在讨论符号表生成的复杂性之前,可以先回顾一下 python 中的名称和绑定。
Names and Binding
在 python 中,对象是通过名称引用的。名称类似于 C ++ 和 Java 中的变量,但不完全相同。
x = 5
在上面的示例中,x 是引用对象 5 的名称。将对 5 的引用分配给 x 的过程称为绑定。绑定导致名称与当前正在执行的程序的最里面的对象相关联。绑定可能发生在许多具体的实例中,例如当提供参数有绑定变量时,会在变量分配或者函数/方法调用期间发生绑定。要注意的是,名称只是符号,符号类型和变量类型之间没有关系。名称只是对实际具有类型的对象的引用。
Code Blocks
代码块对于 python 程序至关重要,因此了解它们对于理解 python 虚拟机内部至关重要。代码块是一段程序代码,在 python 中作为一个单元执行。模块、函数和类都是代码块的例子。在 REPL 上以交互方式键入的命令,使用 -c 选项运行的脚本命令也是代码块。一个代码块具有许多与之相关的命名空间。例如,模块代码块可以访问全局命名空间,而功能代码块可以访问局部 (local) 命名空间和全局 (global) 命名空间。
Namespaces
顾名思义,命名空间是一个上下文,在该上下文中一组给定的名称会绑定到对象上。命名空间在 python 中被实现为字典映射。内置命名空间是命名空间的一个例子,它是一个包含所有内置函数的命名空间,可以通过在终端输入 builtins.dict来访问这个命名空间 (结果相当巨大) 。解释器可以访问多个命名空间,包括全局命名空间,内置命名空间和局部命名空间。这些命名空间是在不同的时间创建的,并且具有不同的生存期。例如,在调用函数时会创建一个新的局部命名空间,并在该函数退出或返回时将其丢弃。全局命名空间是在模块执行开始时创建的,并在调用解释器,并且包含所有内置名称时,内置命名空间会在模块范围内使用在该命名空间中定义的所有名称。这三个命名空间是解释器可用的主要命名空间。
Scopes
scope 是程序的一个区域,在其中一系列绑定名称 (命名空间) 是可见的,并且可以直接使用它们而无需使用任何点符号。在运行时,以下作用域可能是可用的。
具有局部名称的最内部作用域。
如果有的话,闭包函数的作用域 (适用于嵌套函数)。
当前模块的全局作用域。
包含内置命名空间的作用域。
在 python 中使用名称时,解释器将按上述升序搜索范围的命名空间,如果在任何命名空间中均未找到该名称,则会引发异常。 Python 支持静态作用域,也称为词法作用域;这意味着仅检查程序文本即可推断出一组绑定名称的可见性。
注意
Python 有一个古怪的作用域规则,该规则防止在局部作用域内修改全局作用域内对对象的引用。这样的尝试将引发 UnboundLocalError 异常。为了在局部作用域内修改全局作用域内的对象,在尝试进行修改之前,必须将 global 关键字与对象名称一起使用,示例如下。
Listing A3.0: Attempting to modify a global variable from a function
2
3
4
5
6
7
8
>>>> def inc_a(): a += 2
>...
>>>> inc_a()
>Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in inc_a
>UnboundLocalError: local variable 'a' referenced before assignment为了在全局作用域内修改对象,如以下代码段所示,使用了 global 语句。
Listing A3.1: Using the global keyword to modify a global variable from a function
2
3
4
5
6
7
8
>>>> def inc_a():
>... global a
>... a += 1
>...
>>>> inc_a()
>>>> a
>2Python 还有 nonlocal 关键字,该关键字在需要从内部作用域中修改外部非全局作用域中的绑定变量时使用。在使用嵌套函数 (也称为闭包) 时非常方便。以下代码片段有效地说明了非局部关键字的正确用法,该片段定义了一个简单的计数器对象,该计数器对象按升序计数。
Listing A3.2: Creating blocks from an AST
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
>... count = 0
>... def counter():
>... nonlocal count # capture count binding from enclosing not global scope
>... count += 1
>... return count
>... return counter
>...
>>>> counter_1 = make_counter()
>>>> counter_2 = make_counter()
>>>> counter_1()
>1
>>>> counter_1()
>2
>>>> counter_2()
>1
>>>> counter_2()
>2
这一系列函数调用 run_mod _> PyAST_CompileObject _> PySymtable_BuildObject 触发了构建符号表的过程。 PySymtable_BuildObject 函数的两个参数是先前生成的 AST 以及模块的文件名。建立符号表的算法分为两部分。在第一部分中,会访问 AST 的每个节点(作为参数传递给 PySymtable_BuildObject),以建立 AST 中使用的符号的集合。list 3.6 中简单描述了这个过程,当我们讨论构建符号表中所使用的数据结构时,其中使用的术语将会更加的明显。
Listing 3.6: Creating a symbol table from an AST
对于给定AST中的每个节点,
如果节点是代码块的开始:
1.创建新的符号表条目,并将当前符号表设置为此值。
2.将新的符号表压栈到 st_stack。
3.将新符号表添加到先前符号表的子列表中。
4.将当前符号表更新为新符号表。
5.对于代码块节点中的所有节点:
a. 使用 “symtable_visit_XXX” 函数递归访问每个节点,其中 “XXX” 是节点类型。
6.通过从栈中删除当前符号表条目来退出代码块。
7.从栈中弹出下一个符号表条目,并将当前符号表条目设置为该弹出的值
否则:
递归地访问节点和子节点。
在 AST 上运行算法的第一阶段后,符号表条目包含模块中已使用的所有名称,但是它们没有这些名称的上下文信息。例如,解释器无法判断给定变量是全局变量,局部变量还是自由变量。调用 Parser/symtable.c 中的 symtable_analyze 函数将启动符号表生成的第二阶段。算法的此阶段将分配从第一阶段收集符号的作用域(局部、全局或者自由)。 Parser/symtable.c 中的注释很有参考价值,下面了解第二阶段对符号表构造过程。
符号表需要两遍才能确定每个名称的作用域。第一遍通过 symtable_visit_* 函数从 AST 收集原始 facts ,然后第二遍通过遍历第一遍期间创建的 PySTEntryObjects 来分析这些 facts。
在第二遍输入函数时,父级将传递对其子代可见的所有名称绑定。这些绑定用于确定非局部变量是自由变量还是隐式全局变量。在这组可见的名称中必须存在明确声明为非局部的名称,如果不存在,则会引发语法错误。进行局部分析后,它使用一组更新的绑定名称来分析其每个子块。
全局变量也有两种,隐式和显式。使用全局语句声明显式全局变量。隐式全局变量是一个自由变量,编译器在闭包函数的作用域内没有发现对其的绑定。隐式全局可以是全局的或内置的。
Python 的模块和类使用 xxx_NAME 操作码来处理这些名称,以实现稍微奇怪的语义。在这样的代码块中,名称在被分配之前,将会被视为全局的。然后分配后会将其视为局部的。
子代更新自由变量集。如果将局部变量添加到子自由变量集中,则将该变量将标记为 cell 。定义的函数对象必须为可能超出函数 frame 寿命的变量提供运行时存储。在函数返回其父级之前,会从自由变量集中删除 Cell 变量。
尽管这些讨论试图用清晰的语言解释该过程,但仍存在一些令人困惑的点,例如父级传递了对其子级可见的所有绑定名称的集合,父级和子级分别指的是哪些?为了理解这种术语,我们必须查看在创建符号表的过程中使用的数据结构。
Symbol table data structures
符号表生成的两个主要数据结构是:
- 符号表数据结构。
- 符号表条目数据结构。
符号表数据结构如 list 3.7 所示。可以将其视为一张表,由多个条目组成,这些条目保存了给定模块不同代码块中使用的名称的信息。
Listing 3.7: The symtable data structure
1 | struct symtable { |
python 模块可以包含多个代码块,例如多个函数定义,并且 st_blocks 字段是所有存在的代码块到符号表条目的映射。st_top 是正在编译的模块的符号表条目(模块也是代码块),因此它会包含在模块的全局命名空间中定义的名称。st_cur 代表当前正在处理的代码块的符号表条目。模块代码块中的每个代码块都有自己的符号表条目,其中包含该代码块中定义的符号。
Figure 3.1: A Symbol table and symbol table entries.
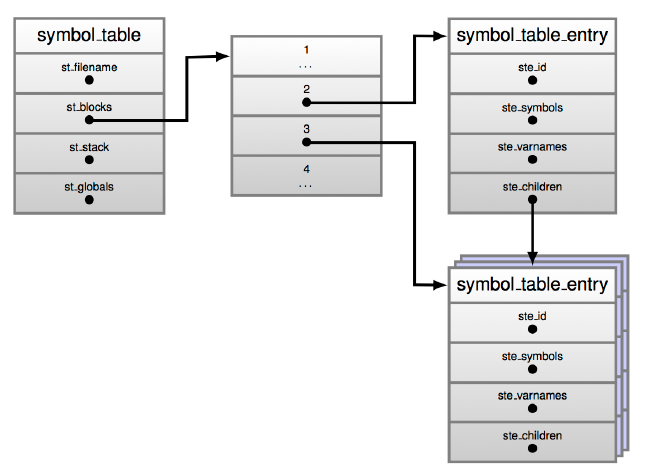
再次查看 Include/symtable.h 中的 _symtable_entry 数据结构对了解此数据结构的作用有很大的帮助。list 3.8 中展示了此数据结构。
Listing 3.8: The _symtable_entry data structure
1 | typedef struct _symtable_entry { |
源代码中的注释说明了每个字段的作用。 ste_symbols 字段是一个映射,其中包含在代码块分析期间遇到的符号/名称;符号映射到的标志是数值,它提供有关使用符号/名称的上下文信息。例如,一个符号可以是函数参数或全局语句定义。list 3.9 中显示了部分在 Include/symtable.h 模块中定义的标志。
1 | /* Flags for def-use information */ |
回到关于符号表的讨论,假设正在编译包含 list 3.10 中所示代码的模块。构建符号表后,将有三个符号表条目。
Listing 3.10: A simple python function
1 | def make_counter(): |
第一个条目是闭包模块,它在局部作用域内定义 make_counter。下一个符号表条目将是功能 make_counter 的条目,并将计数和计数器名称标记为局部。最终的符号表条目是内部 counter 函数。这会将 count 变量标记为 free 。需要注意的一件事是,尽管 make_counter 在模块的块符号表条目中定义为局部,但由于 *st_global 指向 *st_top 符号,因此在模块代码块中将其视为全局定义。
3.5 From AST To Code Objects
生成符号表后,编译器下一步是结合符号表中包含的信息,从 AST 中生成代码对象。处理此步骤的函数在Python/compile.c 模块中实现。生成代码对象的过程也是包含了多步。第一步,将 AST 转换为 python 字节码指令的基本块。此算法类似于生成符号表中使用的算法,即称为 compile_visit_xx 的函数,其中 xx 是节点类型,用于在访问过程中递归访问每个节点类型,并发出 python 字节码指令的基本块。它们之间的基本块和路径隐式表示一个控制流程图。该图显示了在程序执行期间可以采用的代码路径。在第二步中,使用后深度优先搜索遍历对生成的控制流程图进行展平。将图展平后,然后计算跳转偏移并将其用作字节码跳转指令的指令参数。代码对象是从这组指令中发出的。为了更好地了解此过程,请参考 list 3.11 中的 fizzbuzz 函数。
Listing 3.11: A simple python function
1 | def fizzbuzz(n): |
上面函数的 AST 如下图所示。
Figure 3.2: A very simple AST for listing 3.2
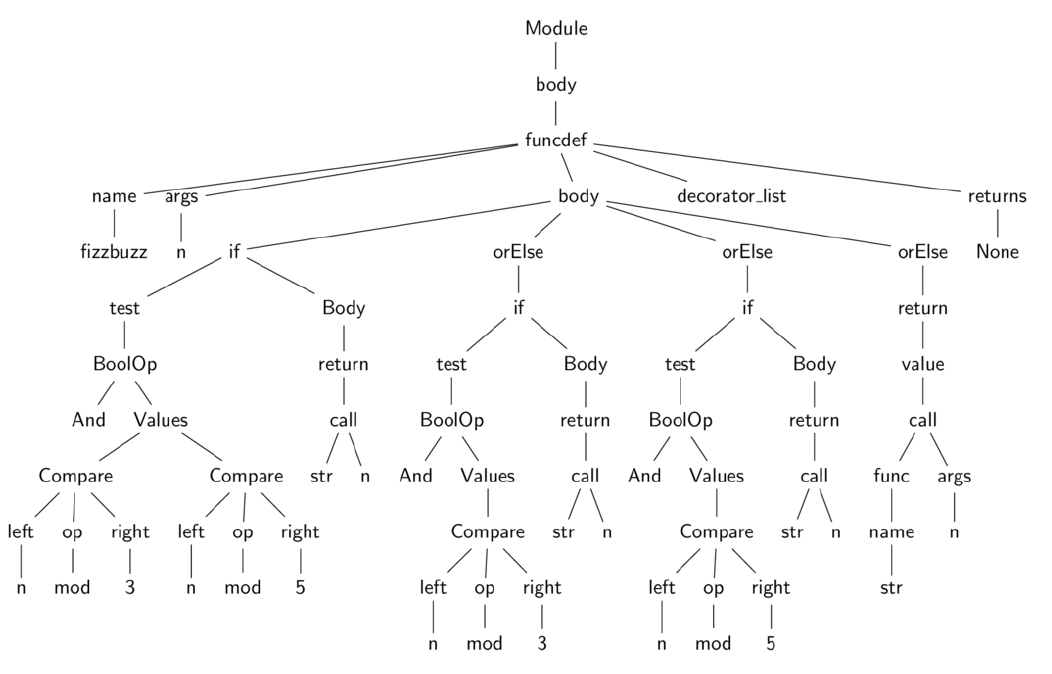
图 3.2 中的 AST 编译为 CFG (the control flow graph) 时,其图形类似于图 3.3 所示。图中省略了空白块。基本块具有单个入口,但可以具有多个出口。下面将会更加详细地描述这些块。
Figure 3.3: Control flow graph for the fizzbuzz function from listing 3.11. The straight line represent normal straight line execution of code while the curved lines represent jumps.
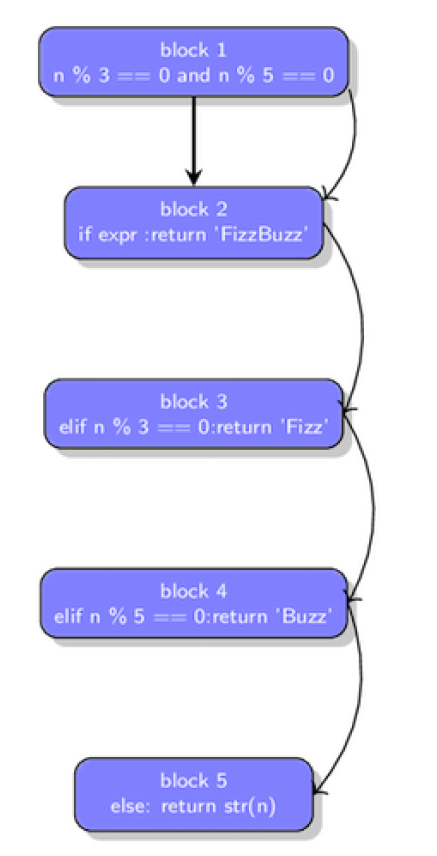
在下面的描述中,仅包括实际的指令。为了使我们能够专注于当前的主题,一些需要参数的指令并未包括在内。
Block 1此块包含映射到图 3.2 中 AST 的 BoolOp 节点的指令。该块中的指令使用以下十一组指令来实现操作 n%3 == 0 和 n%5 == 0 。
1
2
3
4
5
6
7
8
9
10
11LOAD_FAST
LOAD_CONST
BINARY_MODULO
LOAD_CONST
COMPARE_OP
JUMP_IF_FALSE_OR_POP
LOAD_FAST
LOAD_CONST
BINARY_MODULO
LOAD_CONST
COMPARE_OP令人惊讶的是,其余的 if 节点(确定是否应执行该子句的实际测试)未包含在此 block 中。在讨论第二个代码块时,我们就会更加清晰的明白这样的原因。如图 3.3 所示,有两种方法可以退出该 block :直接执行所有操作码或者在执行 JUMP_IF_FALSE_OR_POP 时跳转到代码 block 2。
Block 2 此 block 映射到第一个 if 节点,其中封装了 if 测试和后续的子句。第二个 block 中包含以下四个指令。
1
2
3
4POP_JUMP_IF_FALSE
LOAD_CONST
RETURN_VALUE
JUMP_FORWARD从后面的章节中可以看出,当解释器为 if 语句执行字节码指令时,它从 value stack 中读取一个对象,并根据该对象的真值,执行下一个字节码指令或跳转到指令集的其他部分,然后从那里继续执行。 POP_JUMP_IF_FALSE 是处理该过程的指令。此操作码有一个参数,该参数指定此跳转的目的地。
有人可能想为什么 BoolOp 节点的指令以及 if 语句在不同的块中。为了理解这一点,请记住 python 使用短路求值进行布尔运算,因此在这种情况下,如果 n % 3 == 0 的计算结果为 false,则不会计算 n % 5 == 0。第一次比较后,查看第一个 block 中的指令,您会注意到 JUMP_IF_FALSE_OR_POP 这个指令。该指令是 jump 指令的变体,因此需要一个目标。
JUMP_IF_FALSE_OR_POP 需要一个目标,当布尔表达式中的第一个表达式由于短路操作而求值为 false 时,将在该目标处继续执行指令,在这种情况下,目标是 if 语句中的 POP_JUMP_IF_FALSE 指令。为了使跳转成为可能,我们需要一个不同 block 并且有 if 语句指令的目标去跳转,然后可以计算出进行跳转的偏移量。如果计算了布尔表达式的所有部分,则将在执行 BoolOp 块中的所有指令之后,以 if 块中的指令继续正常执行。
Block 3 映射到第三个 block 的第一个 orElse AST 节点,它包含以下 9 条指令。
1
2
3
4
5
6
7
8
9LOAD_FAST
LOAD_CONST
BINARY_MODULO
LOAD_CONST
COMPARE_OP
POP_JUMP_IF_FALSE
LOAD_CONST
RETURN_VALUE
JUMP_FORWARD可以看到 elif 语句和 n % 3 == 0 以及语句主体都在同一个 block 中。进入此 block 的唯一入口就是跳入该 block ,并且如果 if 结果为 false ,则会通过返回指令或跳转来退出该节点。
Block 4 是就指令而言的Block 3 的镜像,但指令的参数不同。
Block 5 映射到最终的 orElse AST 节点上,并包含以下 4 条指令。
1
2
3
4LOAD_GLOBAL
LOAD_FAST
CALL_FUNCTION
RETURN_VALUELOAD_GLOBAL 将 str 函数作为参数并将其加载到值堆栈中。 LOAD_FAST 将参数 n 加载到堆栈上,而RETURN_VALUE 返回执行 CALL_FUNCTION 指令后在堆栈上的值,即 str(n)。
与上一节一样,我们将会研究用于构建基本块的数据结构,以便于更好地掌握此过程。
The compiler data structure
图 3.4 显示了在生成控制流程图的基本块过程中使用的主要数据结构之间的关系。
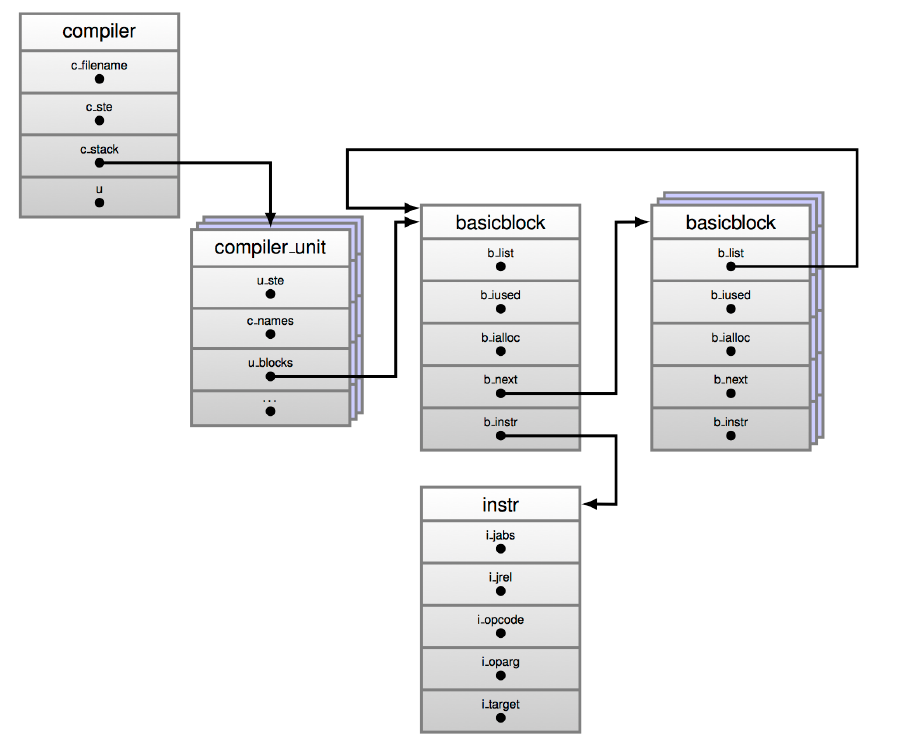
Figure 3.4: The four major data structures used in generating a code object.
最顶层是编译器数据结构,它捕获模块全局编译的过程。list 3.12 中定义了此数据结构。
1 | struct compiler { |
以下是我们感兴趣的字段。
- *c_st: 对上一部分中生成的符号表进行引用。
- *u: 对编译器单元数据结构进行引用。这封装了使用代码块所需的信息。该字段指向正在操作的当前代码块的编译器单元。
- *c_stack: 对 compiler_unit 数据结构堆栈的引用。当一个代码块由多个代码块组成时,此字段将在遇到新块时,会对 compile_unit 数据结构的保存和恢复进行处理。输入新的代码块后,创建新的作用域,然后 editor_enter_scope() 将当前的 compuger_unit *u 推入堆栈 *c_stack 中,创建一个新的 compile_unit 对象,并且当遇到新的模块时将其设置为当前状态。当退出该块时,*c_stack 会从堆栈中弹出,以恢复状态。
对于每个要编译的模块,都会初始化一个编译器数据结构;当遍历为模块生成的 AST 时,会为 AST 中遇到的每个代码块生成一个 editor_unit 数据结构。
The compiler_unit data structure
如下面 list 3.13 所示,compiler_unit 数据结构展示了生成代码块所需的字节码指令所需的信息。当我们查看代码对象时,将会遇到很多在 compiler_unit 中定义的字段。
Listing 3.13: The compiler_unit data strcuture
1 | struct compiler_unit { |
u_blocks 和 u_curblock 字段的引用构成正在编译的代码块的基本块。 *u_ste 字段是对正在编译的代码块的符号表条目的引用。其余字段都可以从名称中得到意义。在编译过程中将遍历组成代码块的不同节点,并且根据给定节点类型是否开始基本块,将创建包含节点指令的基本块,或者将节点的指令添加到现有基本块中。块可以开始新的基本块的节点类型包括但不限于以下类型。
- 功能节点。
- 跳跃到目标。
- 异常处理程序。
- 布尔操作等等。
The basic_block and instruction data structures
基本块数据结构在生成控制流程图的过程中是一个相当有趣的数据结构。基本块是具有一个入口但具有多个出口的指令序列。list 3.14 中显示了 python 虚拟机中使用的 basic_block 数据结构的定义。
Listing 3.14: The basicblock_ data strcuture
1 | typedef struct basicblock_ { |
如前所述,CFG 基本上由基本块和这些基本块之间的连接组成。 *b_instr 字段引用指令数据结构的数组,并且这些数据结构中的每一个都保存一个字节码指令。这些字节码可以在 Include/opcode.h 头文件中找到。指令数据结构如 list 3.15 所示。
Listing 3.15: The instr data strcuture
1 | struct instr { |
看一下 fizzbuzz 函数的 CFG,我们可以看到实际上有两种方法可以从 block 1 到 block 2 。第一种是通过正常执行: 执行完 block 1 中的所有指令之后,在 block 2 中继续执行。另一种方法是通过仅存在于第一个比较操作之后的跳转指令进行。这个跳转的目标是一个基本 block,但实际执行的代码对象对基本 block 一无所知,该代码块仅具有字节码流 (stream of bytecodes),而我们只能通过偏移量对这种 stream 进行索引。我们不得不使用块创建的隐式图作为跳转目标,并将这些 block with offset 替换进指令数组中。这就是基本 block 的组装过程。
Assembling basic blocks
生成 CFG 后,基本块现在包含表示 AST 的字节码指令,但这些块不是线性排序的,对于跳转语句,指令仍将基本块作为跳转目标,而不是相对于指令的相对或绝对偏移。assemble 功能处理 CFG 的线性化和从 CFG 创建代码对象。
首先,assemble 函数向没有 RETURN 语句结束的任意 block 添加 return None 语句的指令,这就是为什么可以定义没有 RETURN 语句的方法。接下来是隐式 CFG 的后序深度优先遍历,为了使块平坦化,后序遍历在访问节点本身之前需要先访问子节点。
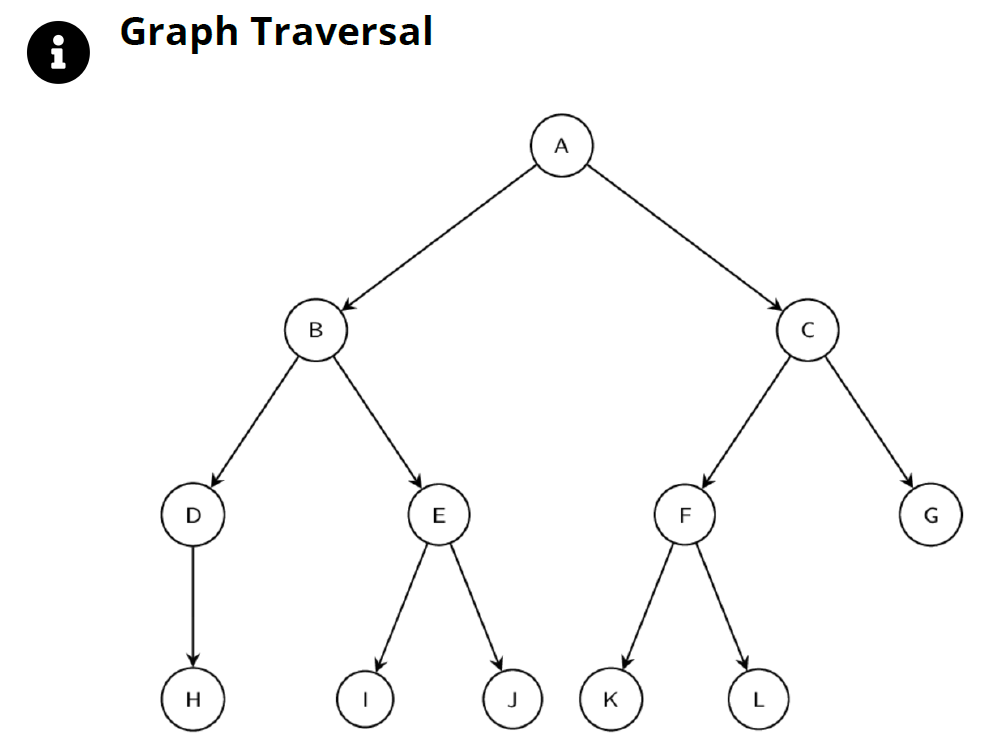
在图的后序深度优先遍历中,我们递归地访问图的左子节点,然后依次访问图的右子节点和节点本身。在图3.5 的图形中,当使用后序遍历对图形进行展平时,节点的顺序为 H _> D _> I _> J _> E _> B _> K _> L _> F _> G _> C _> A 。这与先序遍历 A _> B _> D _> H _> E _> I _> J _> C _> F _> K _> L _> G 或者 中序遍历 H _> D _> B _> I _> E _> J _> A _> K _> L _> F _> C _> G 相反。
list 3.3 中给出的 fizzbuzz 函数的 CFG 是一个相对简单的图形,fizzbuzz 的后顺序遍历的结果是:block 5 _> block 4 _> block 3 _> block 2 _> block 1。如果已经线性化(即展平),则可以通过在展平图上调用 assemble_jump_offsets 函数来计算指令跳转的偏移量。
jump 的组装分为两个阶段。在第一阶段,如 list 3.16 中的代码片段所示,计算每个指令到指令数组的偏移量。这是一个简单的循环,从展平数组的末尾开始,从 0 开始建立偏移量。
Listing 3.16: Calculating bytecode offsets
1 | ... |
在组装 jump 偏移量的第二阶段,然后如 list 3.17 所示计算跳转指令的跳转目标。这涉及计算相对跳转的相对跳转,并用指令偏移量替换绝对跳转的目标。
Listing 3.17: Assembling jump offsets
1 | ... |
计算出跳转偏移后,展平图中包含的指令以相反的后序遍历开始发出。倒置后序是 CFG 的拓扑排序。这意味着对于从顶点 u 到顶点 v 的每个边,在排序顺序中 u 都排在 v 之前。原因很明显,我们希望一个跳转到另一个节点的节点始终位于该跳转目标之前。完成字节码的发送后,可以使用发出的字节码和符号表中包含的信息为每个代码块组合代码对象。生成的代码对象返回到调用函数,标志着编译过程的结束。
4. Python Objects
在本章中,我们将研究 python 对象以及它们在 CPython 虚拟机中的实现。理解 python 对象如何如何进行组织的对于理解 python 虚拟机的内部结构十分重要。我们可以在 Include/ 和 Objects/ 目录中找到此处讨论的大多数来源。毫不奇怪,用 python 实现对象系统非常复杂,我们尽力避免陷入 C 实现的繁琐细节中。首先,我们先来看看 PyObject 结构 —— python 对象系统的主要部分。
4.1 PyObject
粗略查看 CPython 的源码表明 PyObject 结构的随处可见。实际上,正如我们稍后在本节中看到的那样,当解释器循环正在处理执行堆栈上的值时,所有这些值都被视为 PyObjects。如果需要更好的术语,我们将其称为所有 python 对象的超类。实际上,没有任何值被声明为 PyObject,但是可以将指向任何对象的指针强制转换为PyObject。总而言之,任何对象都可以被视为 PyObject 结构,因为所有对象的初始段 (initial segment) 实际上都是 PyObject 结构。
A word on C structs
当我们说没有任何值被声明为 PyObject,但是可以将指向任何对象的指针强制转换为 PyObject 时,我们指的是在 C 语言及其如何解释内存位置数据的实现细节。用于表示 python 对象的 C 结构体只是一组字节,我们可以选择以任何方式解释它们。例如,一个 test 结构体,由 5 个短值组成,每个值 2 个字节,总和最多 10 个字节。在 C 语言中,给定 10 个字节的引用,我们可以将这 10 个字节解释为由 5 个短值组成的 test 结构体,而不管这 10 个字节是否真的是定义为 test 的结构体,但是,当你尝试访问该结构体的字段时,输出也许是乱码。这意味着在给定 n 个表示 python 对象数据的 n 个字节 (其中 n 大于 PyObject 的大小) 的情况下,我们可以将前 n 个字节解释为 PyObject。
PyObject 结构如 list 4.0 所示,它由多个字段组成,这些字段都存在才能将它视为对象。
Listing 4.0: PyObject definition
1 | typedef struct _object { |
_PyObject_HEAD_EXTRA 现在是 C 中的一个宏,它定义了指向先前分配的对象和下一个对象的字段,这些字段形成所有活动对象的隐式双链表。 ob_refcnt 字段用于内存管理,*ob_type 是指向类型对象的指针,该对象指示对象的类型。正是这种类型决定了数据代表着什么,包含的数据类型以及可以对该对象执行的操作类型。以 list 4.1 中的代码段为例,名称 name,指向一个字符串对象,并且对象的类型为 “str”。
Listing 4.1: Variable declaration in python
1 | name = 'obi' |
这里有一个问题,由于类型字段指向类型对象,那么这个类型对象的 *ob_type 字段指向什么?类型对象的 ob_type 实际上指向自身,因此称一个类型对象的类型是类型 (the type of a type is type) 。
A word on reference counting
CPython 使用引用计数进行内存管理。这是一种简单的方法,其中只要创建对对象的新引用 (如 list 4.1 中将名称绑定到对象的情况),对象的引用计数就会增加。反之亦然,每当对一个对象的引用消失 (例如,使用名称上的 del 方法删除该引用) 时,引用计数就会减少。当对象的引用计数变为零时,VM 可以将其释放。在VM 的世界中,Py_INCREF 和 Py_DECREF 用于增加和减少对象的引用计数,它们在我们讨论的许多代码片段中都存在。
VM 中的类型是使用 Objects/Object.h 模块中定义的 _typeobject 数据结构实现的。这是一个 C 结构,其中包含用于大多数功能或每种类型填充的功能集合的字段。接下来我们看一下这个数据结构。
4.2 Under the cover of Types
Include/Object.h 中定义的 _typeobject 结构体充当所有 python 类型的基本结构。此数据结构中定义了大量的字段,这些字段大多是指向为 C 函数的指针,这些函数实现给定类型的某些功能。为方便起见,list 4.2 中复制了 _typeobject 结构定义。
Listing 4.2: PyTypeObject definition
1 | typedef struct _typeobject { |
PyObject_VAR_HEAD 字段是上一节中讨论的 PyObject 字段的扩展;此扩展为具有长度概念的对象添加了一个 ob_size 字段。 python C API 文档 中提供了这个类型对象结构中每个字段的全面说明。需要注意的一点是,结构体中的每个字段都实现了部分类型的行为。部分这些字段可以被我们称为对象接口或协议的一部分,因为它们映射到可以在 python 对象上调用的函数,但是其实际实现方式取决于类型。例如,tp_hash 字段是给定类型的哈希函数的引用,但是如果类型的实例不可哈希,则该字段可以不带值。在该类型的实例上调用 hash 方法时,将调用 tp_hash 字段中的任意函数。类型对象还具有 tp_methods 字段,该类型的引用方法是唯一的。 tp_new 插槽 (slot) 是对创建该类型的新实例的函数的引用,等等。其中某些字段 (例如 tp_init) 是可选的,并不是每种类型都需要运行初始化函数,尤其是当该类型是不可变的 (例如元组) ,但是有些其他字段 (例如tp_new) 是强制性的。
这些字段中还有其他 python 协议的字段,内容如下:
- 数字协议(Number protocol):实现此协议的类型将具有 PyNumberMethods *tp_as_number 字段的实现。该字段是对实现类似于数字运算的一组函数的引用,这意味着该类型将支持在 tp_as_number 集合中实现的算术运算。例如,非数值类型在此字段中有一个条目,因为它支持算术运算,例如 -,<= 等。
- 序列协议(Sequence protocol):实现此协议的类型将在 PySequenceMethods *tp_as_sequence 字段中具有一个值。这意味着该类型将支持某些或所有序列操作,例如 len,in 等。
- 映射协议(Mapping protocol):实现此协议的类型将在 PyMappingMethods *tp_as_mapping 中具有一个值。这样可以使用字典下标语法来设置和访问键-值映射,从而将此类实例视为 python 字典。
- 迭代器协议(Iterator protocol):实现此协议的类型将在 getiterfunc tp_iter 以及 iternextfunc tp_iternext 字段中具有一个值,从而使该类型的实例能够像 python 迭代器一样使用。
- 缓冲区协议(Buffer protocol):实现此协议的类型将在 PyBufferProcs * tp_as_buffer 字段中具有一个值。这些功能将允许访问该类型的实例作为输入/输出缓冲区。
在阅读本章的过程中,我们将更详细地研究构成类型对象的各个字段,但现在,我们将探讨许多不同的类型对象,作为研究“有关如何在实际类型对象中填充这些字段”的具体案例。
4.3 Type Object Case Studies
The tuple type
我们详细查看元组类型,用来了解如何填充类型对象的字段。我们之所以选择它,是因为考虑到实现的规模较小,它相对容易使用——大约一千多行 C 语言(包括文档字符串)。元组类型的实现如 list 4.3 所示。
Listing 4.3: Tuple type definition
1 | PyTypeObject PyTuple_Type = { |
我们看看在这种类型中填充的字段。
PyObject_VAR_HEAD 使用类型对象 PyType_Type 作为类型进行初始化。回想一下,类型对象的类型是 Type。查看 PyType_Type 类型对象可发现 PyType_Type 的类型是其自身。
tp_name 初始化为元组类型的名称。
tp_basicsize 和 tp_itemsize 是元组对象的大小和包含在元组对象中的元素 (items),并对它相应地进行填充。
tupledealloc 是一种内存管理函数,用于在销毁元组对象时对内存进行重新分配。
tuplerepr 是使用元组实例作为参数调用 repr 函数时调用的函数。
tuple_as_sequence 是元组实现的一组序列方法,如元组支持 in, len 等序列方法。
tuple_as_mapping 是元组支持的一组映射方法,在这种情况下,键是整数索引。
tuplehash 是在需要元组对象的哈希值时调用的函数,当元组用作字典的键或在集合中使用时起作用。
PyObject_GenericGetAttr 是引用元组对象的属性时调用的通用函数。我们将在后续部分中介绍属性引用。
tuple_doc 是元组对象的文档字符串。
tupletraverse 是用于遍历元组对象的遍历函数。GC 使用这个功能来帮助检测循环引用。
tuple_iter 是在 tuple 对象上调用 iter 函数时调用的方法。在这种情况下,将返回完全不同的tuple_iterator 类型,因此 tp_iternext 方法没有实现。
tuple_methods 是元组类型的实际方法。
tuple_new 用于创建新的 tuple 类型实例的函数。
PyObject_GC_Del 是另一个引用内存管理功能的字段。
其余具有 0 值的字段保留为空,因为元组的功能不需要它们。以 tp_init 字段为例,元组是不可变的类型,它一旦创建就不能更改,因此除了 tp_new 引用函数中发生的事情除外,不需要任何初始化,因此该字段保留为空。
The type type
我们要关注的另一种类型是 type 类型。它是所有内置类型和用户定义的普通类型的元类 (用户可以定义新的元类),注意在 PyVarObject_HEAD_INIT 中初始化元组对象时如何使用此类型的。在讨论类型时,重要的是区分以 type 为类型的对象和以用户定义类型为类型的对象。这在处理对象中的属性引用时非常重要。
此类型定义了使用类型时使用的方法,并且这些字段与之前章节的方法相似。在创建新类型时 (如我们在后续各节中所见) ,将使用此类型。
The object type
另一个重要的类型是 object 类型,它与 type 类型非常相似。object 类型是所有用户定义类型的根类型,并提供一些默认值,用于填充用户定义类型的类型字段。由于和以 type 作为其类型的类型相比,用户定义的类型的行为方式是不同的。正如我们将在后续部分中看到的那样,object 类型和 type 类型所提供的关于属性解析算法之类的功能之间有很大不同。
4.4 Minting type instances
假定大家对类型的基本类型 (type) 有深刻的理解,那么我们就可以学习类的最基本功能之一,即 使用类创建实例。为了充分理解创建新类型实例的过程,我们要记住,正如我们在区分内置类型和用户定义类型一样,它们两者的内部结构也会有所不同。 tp_new 字段在 python 新类型实例中普遍存在。下面 tp_new 插槽 (slot) 的文档对应该填充的插槽 (slot) 功能进行了很好的描述。
一个可选的指向实例创建函数的指针。如果对于特定类型,该函数为 NULL,那么该类型无法被调用,从而创建出新的实例;还有其他创建实例的方法,例如工厂函数。函数签名是:
1 | PyObject * tp_new(PyTypeObject *subtype,PyObject * args,PyObject * kwds) |
subtype 参数是要创建的对象的类型。 args 和 kwds 参数表示调用该类型所需的位置参数和关键字参数。subtype 不必等于调用 tp_new 函数的类型。它可能是该类型的子类型 (但不是无关类型) 。 tp_new 函数需要调用subtype _> tp_alloc(subtype,nitems) 为对象分配空间,然后仅在绝对必要的情况下进行更多的初始化。可以安全地忽略或重复进行的初始化应该放在 tp_init 处理程序中。一个好的经验法则是,对于不可变类型,所有初始化都应在 tp_new 中进行,而对于可变类型,大多数初始化应推迟到 tp_init 中进行。
此字段由子类型继承,但不是由 tp_base 为 NULL 或 &PyBaseObject_Type 的静态类型继承。
我们将使用上一节中的元组类型作为内置类型的示例。元组类型的 tp_new 字段引用 list 4.4 中所示的tuple_new 方法,该方法处理新的元组对象的创建。为了创建一个新的元组对象,需要调用这个函数并且取消相关的引用。
Listing 4.4: tuple_new function for creating new tuple instances
1 | static PyObject * tuple_new(PyTypeObject *type, PyObject *args, |
忽略 list 4.4 中创建元组的第一个和第二个条件,我们遵循第三个条件,顺着代码 if (arg == NULL) return PyTuple_New(0) 从而了解其工作原理。忽略 PyTuple_New 函数中的优化,函数中创建新元组对象的部分是 op = PyObject_GC_NewVar( PyTupleObjectl, &PyTuple_Type, size ) 调用,该调用基本上为堆上的 PyTuple_Object 结构体的实例分配内存。这是内建类型和用户定义类型的内部表示之间的一个明显区别,内建类型的实例 (例如元组) 实际上是 C 的结构体。这可能是为了提高效率。那么支持元组对象的 C 结构体看起来像什么?可以在 Include/ tupleobject.h 中找到它作为 PyTupleObject 类型定义 , 如 list 4.5 中所示。
Listing 4.5: PyTuple_Object definition
1 | typedef struct { |
PyTupleObject 是定义为具有 PyObject_VAR_HEAD 和 PyObject 类型的指针数组的结构体:ob_items 。与使用 python 数据结构表示实例相比,这种实现非常高效。
回想一下,对象是方法和数据的集合。在这种情况下,PyTupleObject 提供了空间来保存每个元组对象包含的实际数据,因此我们可以在堆上分配多个 PyTupleObject 实例,但是这些实例都是单个 PyTuple_Type 类型的引用,该类型提供可以对这些数据进行操作的方法。
现在考虑一个用户定义的类,如 list 4.6 所示。
Listing 4.6: User defined class
1 | class Test: |
Test 类型是 Type 类型的实例对象。要创建 Test 类型的实例,需要调用 Test 类型:Test() 。和往常一样,我们可以顺其自然的理清类型对象被调用时发生的事情。 Type 类型具有一个函数引用:type_call,它填充在 tp_call 字段内,并且每当在 Type 实例上使用调用符号时,都会取消引用。list 4.7 中展示了 type_call 函数实现的代码片段。
Listing 4.7: A snippet of type_call function definition
1 | ... |
list 4.7 显示了调用 Type 对象的实例时,就会取消对 tp_new 字段的引用,并调用了所引用的任意函数从而得到一个新的实例。如果 tp_init 存在,就会在新实例上调用它,从而对新实例进行初始化。这个过程为内置类型提供了解释,因为它们已经定义了自己的 tp_new 和 tp_init 函数,但是用户定义的类型呢?大多数情况下,用户不会为新类型定义 new 函数 (在定义时,它会在类创建期间进入 tp_new 字段) 。答案还取决于实现 Type 中 tp_new 字段的 type_new 函数。在创建用户定义的类型时,如自定义类 Test, type_new 函数会去检查是否存在基本类型 (超类/父类) ,如果不存在,则将 PyBaseObject_Type 类型添加为默认基本类型,如 list 4.8 所示。
Listing 4.8: Snippet showing how the PyBaseObject_Type is added to list of bases
1 | ... |
这个默认的基本类型也是在 Objects/typeobject.c 模块中定义的,其中包含各个字段的一些默认值。这些默认值中包括 tp_new 和 tp_init 字段的值。这些值是在用户定义类时被解释器调用。在用户定义的类实现自己的方法 (例如 init __ , __ new 等) 的情况下,会调用这些值,而不是 PyBaseObject_Type 类型的值。
有人可能会注意到,我们没有提到任何对象结构,例如元组对象结构:tupleobject,并且提问:如果没有为用户定义的类定义对象结构,那么如何处理对象实例以及未映射到该类型插槽中的对象属性在哪里 (if no object structures are defined for a user defined class then how are object instances handled and where do objects attributes that do not map to slots in the type reside) ?这与 tp_dictoffset 字段 (类型对象中的数字字段) 有关。实例实际上是作为 PyObjects 创建的,但是当实例类型中的偏移值非零时,它会指定实例属性字典与实例(PyObject) 本身之间的偏移量,如图 4.0 所示,因此对于 Person 类型的实例来说,可以通过将此偏移量添加到PyObject 原始内存位置来估计属性字典的位置。
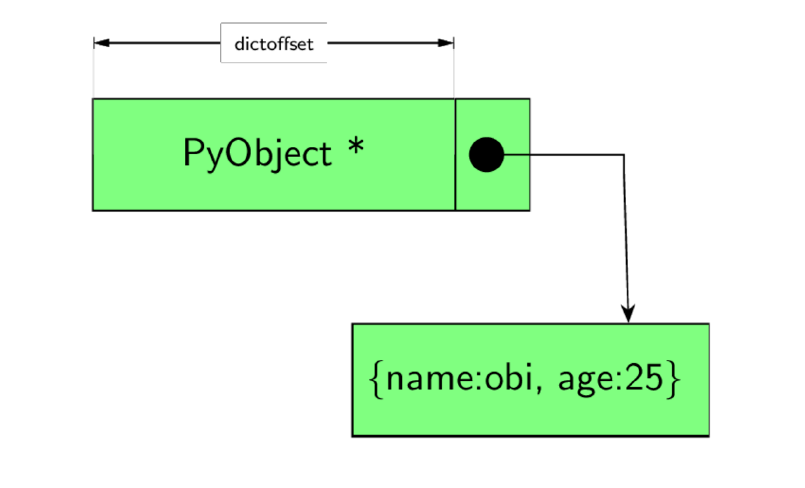
Figure 4.0: How instances of user defined types are structured.
例如,如果实例 PyObject 的值为 0x10,偏移量为 16,则包含实例属性的字典可以在 0x10 + 16 处找到。正如我们在下一节中看到的一样,这不是实例存储其属性的唯一方法。
4.5 Objects and their attributes
面向对象编程的核心就是类及其属性 (变量和方法) 。通常来说,类和实例使用 dict 数据结构存储其属性,但并不是所有的类和实例都是这样,例如有些定义了 slots 的类和实例。如上一节所说的那样,在两个位置中的某个位置找到 dict 数据结构取决于对象的类型。
- 对于具有 Type 类型的对象,类结构中的 tp_dict 插槽 (slot) 是指向 dict 的指针,该 dict 包含这个类的值,变量和方法。通常意义上来说,我们说类对象的数据结构中的 tp_dict 字段是指向类的 dict 的指针。
- 对于具有非 Type 类型的对象 (即用户定义类型的实例) ,该 dict 数据结构 (如果存在) 位于表示该对象的 PyObject 结构后面。对象类型的 tp_dictoffset 值给出了从对象开始到包含实例属性 dict 的偏移量。
做一个简单的字典访问来获取属性似乎很简单,但这还并没有结束。实际上,与检查 Type 实例的 tp_dict 值或用户定义类型的实例的 tp_dictoffset 处的 dict 相比,搜索属性更加复杂。为了更加全面的理解,我们必须讨论描述符协议,这个协议是 python 属性引用的核心。
《Descriptor HowToGuide》是对一个对描述符很好的介绍,因此这里仅提供了对描述符的粗略描述。简而言之,描述符是一个对象,它实现了描述符协议的 get, set 或 delete 特殊方法。list 4.9 显示了python 中每种方法的签名。
Listing 4.9: The Descriptor protocol methods
1 | descr.__get__(self, obj, type=None) --> value |
仅实现 get 方法的对象是非数据描述符,因此它们在初始化后表现为只读,而实现 get 和 set 的对象是数据描述符,这意味着此类描述符对象是可写的。我们对描述符及其在表示对象属性中的应用感兴趣。list 4.10 中的 TypedAttribute 描述符是用于表示对象属性的描述符的示例。
Listing 4.10: A simple descriptor for type checking attribute values
1 | class TypedAttribute: |
对用于表示类的任何属性,TypedAttribute 描述符类会强制执行基本类型检查。要注意的是,描述符仅在类级别而不是实例级别(即 list 4.11 所示的 init 方法)中定义时才有效。
Listing 4.11: Type checking on instance attributes using TypedAttribute descriptor
1 | class Account: |
仔细思考一下,只有在类型级别定义此类描述符才有意义,因为如果在实例级别定义,则对该属性的任何分配都将覆盖该描述符。必须阅读 python vm 源代码,以了解 基本的描述符对于 python 来说是什么。描述符提供了 Python 中的属性,静态方法,类方法和许多其他的功能。为了具体说明描述符的重要性,需要考虑用来从实例定义的实例 b 中解析属性的算法,如 list 4.12 所示。
Listing 4.12: Algorithm for find a referenced attribute in an instance of a user defined type
- type(b).dict 被用来搜索属性名称。如果名称被搜索到了并且其是一个数据描述符,调用描述符的 get 方法会返回相应的结果。如果属性名称没有被搜索到,然后所有的在 *mro* 中的基类都以相同的方式进行搜索。
- b.dict 被搜索并且如果属性名称在这里被搜索到了,它就会返回.
- ,如果从 1 中得到的名称是一个非数据描述符,那么就会返回调用 get 的结果。
- 如果名称没有被找到,那么就会抛出 AttributeError 或者 如果是用户定义的类型就会调用 getattr().
list 4.12 中的算法表明,在属性引用期间,我们首先会去检查描述符对象;它还说明了 TypedAttribute 描述符如何能够表示对象的属性:每当引用诸如 b.name 之类的属性时,都会在 Account 类对象中搜索该属性,在这种情况下,会找到 TypedAttribute 描述符并会调用它的 get 方法。 TypedAttribute 示例说明了一个描述符,但是它相当刻意。为了真正了解描述符对于语言核心的重要性,我们会用一些例子来说明如何应用描述符。
请注意,list 4.12 中的属性引用算法与类型为 type 时使用的属性引用算法是不同的。list 4.13 显示了类型为type 的算法。
Listing 4.13: Algorithm to find a referenced attribute in a type
type(type).dict 用来搜索属性名称。如果名称被找到并且是一个数据描述符,调用描述符的 get 方法会返回相应的结果。如果属性名称没有被搜索到,然后所有的在 *mro* 中的基类都会以用相同的方式进行搜索。
type.dict 以及所有他的基类都是用来搜索属性名称。如果名称被找到并且它是一个描述符,那么返回一个调用它的 get 方法的值;如果它是一个普通的方法,那么返回它自己。
如果一个值在 1 中被发现并且它是一个非数据描述符,那么返回一个调用它的 get 方法的值。
如果一个值在 1 中被发现并且不是一个描述符,那么返回它本身。
Examples of Attribute Referencing with Descriptors inside the VM
描述符在 Python 中的属性引用中起着非常重要的作用。思考一下本章前面讨论的类型数据结构。任何希望被视为描述符的类型实例都可以填充类型数据结构中的 tp_descr_get 和 tp_descr_set 字段。函数对象是展示其工作原理的好地方。
给一个类,如 list 4.11 中的 Account,考虑一下,当我们从 Account 类中引用 name_balance_str 方法,以及从 list 4.14 中所示的实例中引用同样的方法时会发生什么。
Listing 4.14: Illustrating bound and unbound functions
1 | >> a = Account() |
查看 list 4.14 中的代码段,尽管我们似乎引用了相同的属性,但返回的实际对象的值和类型不同。当从Account 类型引用时,返回的值是函数类型,但是从 Account 类型的实例引用时,返回的结果是绑定方法类型。返回不同类型的原因是因为函数也是描述符。list 4.15 显示了函数对象类型的定义。
Listing 4.15: Function type object definition
1 | PyTypeObject PyFunction_Type = { |
函数对象使用 func_descr_get 函数填充 tp_descr_get 字段,因此函数类型的实例是非数据描述符。list 4.16 显示了 funct_descr_get 方法的实现。
Listing 4.16: Function type object definition
1 | static PyObject * func_descr_get(PyObject *func, PyObject *obj, PyObject *type){ |
如上一节所述,可以在类型属性解析或实例属性解析期间调用 func_descr_get。当从类中调 func_descr_get 时就是调用 local_get(attribute, (PyObject *)NULL, (PyObject *)type),而从用户定义的类型的实例属性引用中调用时,调用签名为 f(descr, obj, (PyObject *)Py_TYPE(obj))。仔细阅读 list 4.16 中 func_descr_get 的实现,我们看到如果实例为 NULL,则函数将返回其自身,而当我们将实例传递给函数调用时,则会使用该函数和实例创建一个新的方法对象。这些总结了 python 如何使用描述符为相同的函数引用返回不同的类型。
- 当在类中定义方法时,我们将 self 参数用作任何实例方法的第一个参数,因为实际上,实例方法将实例(按惯例称为self)作为第一个参数。如 b.name_balance_str() 与 type(b).name_balance_str(b) 的调用实际上是相同。之所以能够调用 b.name_balance_str(),是因为 b.name_balance_str 返回的值是一个方法对象,该对象是 name_balance_str 的一个简单封装,实例已经绑定到该方法了。因此,当我们进行诸如 b.name_balance_str() 之类的调用时,该方法使用绑定的实例作为封装函数的参数,从而向我们隐藏这个细节。
关于描述符的重要性有一些其他的示例,如 list 4.17 中的代码片段,该代码片段显示了从内置类的实例和用户定义类的实例访问 dict 属性的结果。
Listing 4.17: Accesing the dict attribute from an instance of the builtin type and an instance of a user defined type
1 | class A: |
从 list 4.17 中可以看出,当引用 dict 属性时,两个对象都不返回普通的字典类型。类的实例返回一个支持所有常用字典功能的字典映射,类对象似乎返回了一个我们无法分配的映射代理。因此,这些对象的属性的引用方式有所不同。后面的几节中我们会对属性搜索算法进行回顾。第一步是在对象类型的 dict 中搜索属性,因此我们继续对 list 4.18 中的两个对象执行此操作。
Listing 4.18: Checking for dict in type of objects
1 | type(type.__dict__['__dict__']) # type of A is type |
我们看到两个对象的 dict 属性都是由数据描述符表示的,这就是可以得到不同的对象类型的原因。我们想找出在此描述符的内部发生了什么,如函数和绑定方法。一个很好的切入点就是 Objects/typeobject.c 模块和 type 类的定义。tp_getset 字段中包含了一个 C 结构体组成的数组 (PyGetSetDef 值) ,如 list 4.19 所示。这是描述符对象插到 tpye 类 dict 属性中的值的集合,这是类型对象的 tp_dict 槽 (slot) 指向的映射。
Listing 4.19: Checking for dict in type of objects
1 | static PyGetSetDef type_getsets[] = { |
这些值不是唯一将描述符插入类型 dict 的值,还有其他的值,例如 tp_members 和 tp_methods 值,这些描述符在类型初始化期间创建并插入 tp_dict 。在类上调用 PyType_Ready 函数时,会将这些值插入 dict 中。作为PyType_Ready 函数初始化过程的一部分,将为 type_getsets 中的每个条目创建描述符对象,然后将其添加到tp_dict 映射中:Objects/typeobject.c 中的 add_getset 函数将对此进行处理。回到我们的 dict 属性,我们知道类型初始化之后,dict 属性存在于类型的 tp_dict 字段中,因此让我们看看该描述符的 getter 函数是做什么的。 getter 函数是 list 4.20 中所示的 type_dict 函数。
Listing 4.20: Getter function for an instance of type
1 | static PyObject * type_dict(PyTypeObject *type, void *context){ |
tp_getattro 字段指向该函数,该函数是用于获取任何对象属性的第一个调用入口。对于类对象,它指向type_getattro 函数。这个方法又实现了 list 4.13 中描述的属性搜索算法。dict 属性的 dict 类中的描述符所调用的函数是 list 4.19 中给出的 type_dict 函数。这里的返回值是包含类属性的实际字典的字典代理;这解释了查询类对象的 dict 属性时返回的是 mappingproxy 类型。
那么,用户定义的类 A 的实例又如何解析 _dict_\ 属性呢?回想一下,A 实际上是 type 类的对象,因此我们在 Object/typeobject.c 模块中搜寻以了解如何创建新的类。 PyType_Type 的 tp_new 插槽 (slot) 包含用于创建新类型对象的 type_new 函数。仔细阅读函数中的所有创建类的代码,如 listing 4.21 。
Listing 4.21: Setting tp_getset field for user defined type
1 | if (type->tp_weaklistoffset && type->tp_dictoffset) |
假设第一个条件为 true,则 tp_getset 字段将填充 list 4.22 中所示的值。
Listing 4.22: The getset values for instance of type
1 | static PyGetSetDef subtype_getsets_full[] = { |
调用 (*tp > tp_getattro)(v, name) 时,将会调用 tp_getattro 字段,其包含指向 PyObject_GenericGetAttr 的指针。该函数负责为用户定义的类实现属性搜索算法。对于 _dict 属性,在对象类型的 dict 中找到描述符,而描述符的 get 函数是 list 4.21 中在 dict 属性定义的 subtype_dict 函数。list 4.23 显示了 subtype_dict 的 getter 函数。
Listing 4.23: The getter function for __ attribute of a user-defined type
1 | static PyObject * subtype_dict(PyObject *obj, void *context){ |
当对象实例处于继承层次中时,get_builtin_base_with_dict 会返回一个值,因此该实例忽略此函数是没问题的。 PyObject_GenericGetDict 对象被调用。list 4.24 显示了 PyObject_GenericGetDict 和实际获取实例字典的相关的帮助。实际上获取 dict 函数的是 _PyObject_GetDictPtr 函数,该函数查询对象的 dictoffset 并使用该函数计算实例 dict 的地址。在此函数返回空值的情况下,PyObject_GenericGetDict 可以继续向调用的函数返回一个新字典。
Listing 4.24: Fetching dict attribute of an instance of a user defined type
1 | PyObject * PyObject_GenericGetDict(PyObject *obj, void *context){ |
该解释简要总结了如何根据类型使用描述符来实现自定义属性访问。在整个VM中,对于使用描述符执行属性访问的其他实例,使用上述相同策略。描述符在VM中无处不在。 slots,静态方法和类方法,属性只是使用描述符实现的语言功能的进一步示例。
4.6 Method Resolution Order (MRO)
在讨论属性引用时,我们已经提到了 mro,但是由于没有进行过多讨论,因此在本节中,我们将对 mro 进行更加详细的介绍。在 python 中,类可以属于多重继承的层次结构,因此当一个类从多个类继承时,需要一种顺序来搜索方法。正如我们在属性参考解析算法中所看到的那样,在搜索其他非方法的属性时,实际上也是使用了这种称为 Method Resolution Order (MRO) 的顺序。 “ Python 2.3 Method Resolution Order” 一文是一篇出色且易于阅读的文档,介绍了python中使用的方法解析算法。这里总结了主要要点。
当类型从多个基本类型继承时,Python使用C3⁸算法来构建方法的解析顺序(在此也称为线性化)。清单4.25显示了一些用于解释该算法的符号。
1 | C1 C2 ... CN 指示类的列表 [C1, C2, C3 .., CN] |
考虑多重继承层次结构中的类型C,其中 C 继承自基本类型B1,B2,…,BN,则 C 的线性化是 C 的加上父项的线性化与父项的列表的总和。L[C (B1 … BN) ] = C + merge (L [B1] … L [BN], B1 … BN) 。没有父对象的对象类型的线性化是微不足道的,L[object] = object。合并操作是根据以下算法计算的:
- 以第一个列表的开头,即L[B1][0];如果此头不在任何其他列表的尾部,则将其添加到 C 的线性化中,然后从合并中的列表中将其删除,否则,查看下一个列表的 head 并使用它,如果它是一个好的 head 然后重复该操作,直到所有类都被删除,或者不可能找到好的 head 。在这种情况下,不可能进行合并,Python 2.3 将拒绝创建类 C 并且引发异常。
使用此算法无法线性化某些层次结构的类,在这种情况下,VM会引发错误,并且不会创建此层次结构的类。
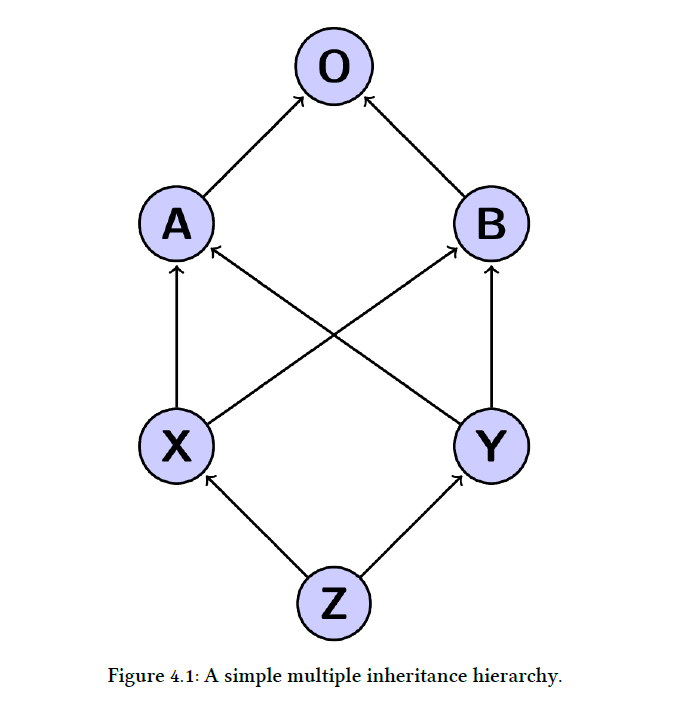
假设我们具有如图 4.1 所示的继承层次结构,则创建 mro 的算法将从层次结构的顶部开始依次为 O,A 和 B。O,A 和 B 的线性化很简单:
Listing 4.26: Calculating linearization for types O, A and B from figure 4.1
L[O] = O
L[A] = A O
L[B] = B O
可以将 X 的线性化计算为L[X] = X + merge(AO, BO, AB)
A 是一个很好的 head,因此将其添加到线性化中,然后剩下的就是计算merge(O, BO, B)。 O 不是好的 head,因为它位于 BO 的尾部,因此我们跳到下一个序列。 B是一个很好的 head ,因此我们将其添加到线性化中,然后剩下的就可以计算归并为 O 的merge(O, O)。所得的 X的 线性化L [X] = X A B O。
使用与上述相同的过程, Y 的线性化的计算如 list 4.27 所示:
Listing 4.27: Calculating linearization for type Y from figure 4.1
L[Y] = Y + merge(AO, BO, AB)
= Y + A + merge(O, BO, B)
= Y + A + B + merge(O, O)
= Y A B O
计算 X 和 Y 的线性化后,我们现在可以计算 Z 的线性化,如 list 4.28 所示。
Listing 4.28: Calculating linearization for type Z from figure 4.1
L[Z] = Z + merge(XABO, YABO, XY)
= Z + X + merge(ABO, YABO, Y)
= Z + X + Y + merge(ABO, ABO)
= Z + X + Y + A + merge(BO, BO)
= Z + X + Y + A + B + merge(O, O)
= Z X Y A B O
5. Code Objects
在本文的这部分中,我们探索的内容是代码对象。代码对象是 python 虚拟机操作的核心部分。 代码对象封装了 python 虚拟机的字节码;我们可以将字节码称为 python 虚拟机的汇编语言。
顾名思义,代码对象代表着已经编译的并且可执行 python 代码。在讨论 python 源代码的编译之前,我们已经见过了代码对象。正如 python 文档中所述,每当编译 python 代码块时,都会生成代码对象。
Python 程序是由代码块构成的。块是作为一个单元 (unit) 执行的一段 Python 程序文本。块有以下类型:模块,函数体和类的定义。交互键入的每个命令都是一个块。脚本文件 (作为标准输入给解释器或指定作为解释器命令行参数的文件) 是代码块。脚本命令 (在解释器命令行上使用 “_c” 选项指定的命令) 是代码块。传递给内置函数 eval() 和 exec() 的字符串参数是一个代码块。
代码对象包含可运行的字节码指令,这些指令在运行时会更改 python 虚拟机的状态。给定一个函数,我们可以使用函数的 code 属性访问函数主体的代码对象,如以下代码片段所示。
Listing 5.1: Function code objects
1 | def return_author_name(): |
对于其他代码块,可以通过编译这些代码来获取该代码块的代码对象。 在 python 解释器中 compile 函数为此提供了便利。代码对象带有许多在执行时由解释器循环使用的字段,在下面部分中,我们将介绍其中的一些字段。
5.1 Exploring code objects
了解代码对象的一个好办法就是编译一个简单的函数,然后检查由该函数生成的代码对象。我们使用函数 fizzbuzz 来作为实验的对象,如 list 5.2 所示。
Listing 5.2: Function code objects attributes of Fizzbuzz function
1 | co_argcount = 1 |
除了包含乱码的 co_lnotab 和 co_code 字段,其它打印出来的字段的含义都是显而易见的。我们将会解释这些字段及其对 python 虚拟机的重要性。
- co_argcount:这是代码块参数的数量。只有函数代码块具有这个值。该值在编译过程中被设置为代码块 AST 的参数集合的长度。执行循环 (evaluation loop) 在代码执行 (code evaluation) 过程中利用这些变量进行完整性的检查,例如检查所有变量是否存在以及是否用于存储局部变量。
- co_code:这包扩了执行循环 (evaluation loop) 执行的字节码指令序列。这些字节码指令序列中的每一个字节码指令都由一个 opcode 和一个 oparg (opcode 所在的参数) 组成的。例如,co.co_code[0] 返回指令的第一个字节,124 映射到 python LOAD_FAST 操作码上。
- co_consts:此字段是常量的列表,例如代码对象中包含的字符串和数字。上面的示例显示了 fizzbuzz 函数这个字段的内容。这个列表中包含的值是代码执行必不可少的,因为它们是 LOAD_CONST opcode 引用的值。字节码指令 (例如 LOAD_CONST) 的操作数参数是此常量列表的索引。例如,思考 FizzBuzz 函数的 co_consts 值,其值为 (None, 3, 0, 5, “FizzBuzz”, “Fizz”, “ Buzz”) ,然后与下面的反汇编代码对象进行对比。
Listing 5.3: Cross section of bytecode instructions for Fizzbuzz function
1 | 0 LOAD_BUILD_CLASS |
回想一下,在编译过程中,如果在函数末尾没有 return 语句,则添加 return None,因此我们可以判断出偏移量为 74 的地方的字节码指令是一个值为 None 的 LOAD_CONST 指令。操作码的参数为 0, 我们可以看到,在 LOAD_CONST 指令实际加载的 None 值在常量列表里的索引为 0 。
4. co_filename:顾名思义,此字段包含文件的名称,该文件包含创建代码对象的源代码。
5. co_firstlineno:这里给出了源代码对象开始所在的行号。在如调试代码之类的活动中起着非常重要的作用。
6. co_flags:此字段指示代码对象的类型。例如,当代码对象是协程对象时,该 flag 会被设置为 0x0080 。还有一些其他的 flags ,例如 CO_NESTED 指示一个代码对象是否嵌套在另一个代码块中,CO_VARARGS 指示一个代码块是否具有可变参数等等。这些 flags 影响字节码 (Bytcode) 执行期间执行循环的行为。
7. co_lnotab:包含一个字节字符串,用于计算字节码偏移量处的指令所对应的源行号。例如,dis 函数在计算指令的行号时会使用此功能。
8. co_varnames:这是在代码块局部中定义的名称的数量。将此与 co_names 对比。
9. co_names:这是在代码对象内使用的非局部名称的集合。例如,list 5.4 中的代码段引用了非局部变量 p 。
Listing 5.4: Illustrating local and non-local names
1 | def test_non_local(): |
list 5.5 中显示了对 list 5.4 中函数代码对象的自省的结果。
Listing 5.5: Illustrating local and non-local names
1 | co_argcount = 0 |
从这个例子中可以看出,c_names 和 co_varnames 之间的区别是显而易见的。 co_varnames 引用局部定义的名称,而 co_names 引用非局部定义的名称。请注意,只有在程序执行期间,如果找不到变量 p,才会引发错误。list 5.6 中显示了 list 5.4 中该函数的字节码指令,这里如何生效是显而易见的。
Listing 5.6: Bytecode instructions for test_non_local function
1 | 0 LOAD_GLOBAL 0 (0) |
注意我们有一个 LOAD_GLOBAL 指令而不是上一个示例中看到的 LOAD_FAST 指令。当我们稍后讨论执行循环 (evaluation loop) 时,我们将会讨论执行循环 (evaluation loop) 所执行的优化,该优化利用了 LOAD_FAST 指令。
- co_nlocals:这是一个数值,它代表了代码对象使用的局部名称的数量。在 list 5.4 的示例中,唯一使用的局部变量是 x,因此对于该函数的代码对象来说,该值为 1。
- co_stacksize:python 虚拟机是基于堆栈的,即用于执行 (evaluation) 和执行结果 (results of evaluation) 的值可从执行堆栈读取或写入执行堆栈。这个 co_stacksize 值是代码块执行期间任意时刻执行栈上存在的最大 item 数量。
- co_freevars:co_freevars 字段是在代码块内定义的自由变量的集合。此字段与形成闭包的嵌套函数密切相关。不同于全局变量,自由变量是在一个块内使用的但未在该块内定义的变量。list 5.7 所展示的例子说明了自由变量的概念。
Listing 5.7: A simple nested function
1 | def f(*args): |
对于 f 函数的代码对象,co_freevars 字段为空,而 g 函数的代码对象中 co_freevars 的值为 x 。自由变量与单元变量 (cell variables) 密切相关。
13. co_cellvars:co_cellvars 字段是名称的集合,在执行代码对象期间必须创建单元 (cell) 用来存储对象。以list 5.7 中的代码段为例,函数 f 的代码对象的 co_cellvars 字段仅包含名称 x,而嵌套函数的代码对象的co_cellvars 字段为空;回想一下有关自由变量的讨论,嵌套函数的代码对象的 co_freevars 集合仅包含 x 。这说明了单元变量和自由变量之间的关系:嵌套范围内的自由变量是闭包范围内的单元变量。在代码对象执行期间,将创建特殊的单元对象以将值存储在此单元格变量集合中。之所以如此,是因为该字段中的每个值都被嵌套的代码对象使用,它们的生存期可能会超过闭包代码对象的生存时间,因此此类值必须存储在代码对象执行完成时不会释放的位置。
The bytecode - co_code in more detail.
如前所述,代码对象的实际虚拟机指令字节码包含在代码对象的 co_code 字段中。例如,来自 fizzbuzz 函数的字节代码是 list 5.7 中所示的字节字符串。
Listing 5.7: Bytecode string for fizzbuzz function
1 | b'|\x00d\x01\x16\x00d\x02k\x02r\x1e|\x00d\x03\x16\x00d\x02k\x02r\x1ed\x04S\x00n,|\x0\ |
为了获得人类可读的字节字符串版本,我们使用 dis 模块中的 dis 函数来提取人类可读的打印输出,如list 5.8 所示。
Listing 5.8: Bytecode instruction disassembly for fizzbuzz function
1 | 7 0 LOAD_FAST 0 (n) |
输出的第一列显示该指令的行号。多个指令可以映射到同一行号。使用来自代码对象的 co_lnotab 字段的信息来计算此值。第二列是给定指令与字节码开头的偏移量。假设字节码字符串包含在数组中,则此值是可以在该数组中找到给定指令的索引。第三列是实际的人类可读指令操作码;完整的操作码可以在 Include/opcode.h 模块中找到。第四列是指令的参数。
第一条 LOAD_FAST 指令的参数为 0 。此值是 co_varnames 数组的索引。最后一列是参数的值由 dis 函数提供,以方便使用。一些参数不采用显式参数。请注意,BINARY_MODULO 和 RETURN_VALUE 指令没有任何显式参数。回想一下,python 虚拟机是基于堆栈的,因此这些指令可以从堆栈顶部读取值。
字节码指令的大小为两个字节:一个字节用于操作码,第二个字节用于操作码的参数。如果操作码不带参数,则第二个参数字节为 0 。 在写这本书期间,Python 虚拟机在机器上使用一些字节序 (endian) 字节编码,因此 16 位代码的结构如图 5.0 所示,其中操作码占据了较高的 8 位,操作码的参数占据了 8 位。

Figure 5.0: Bytecode instruction format showing opcode and oparg
有时候,操作码的参数可能无法放入默认的单个字节中。对于这些类型的参数,python 虚拟机使用 EXTENDED_ARG 操作码。 python 虚拟机的做法是当接受一个太大而无法容纳一个字节的参数时,将其拆分为两个字节 (我们假设此处可以容纳两个字节) :最高有效字节是 EXTENDED_ARG 操作码的参数,而最低有效字节是其实际操作码的参数。 EXTENDED_ARG 操作码将在操作码序列中的实际操作码之前出现,然后可以通过向右移动or’ing 参数的其他部分参数一起来重构操作码和参数。例如,如果希望将值 321 作为参数传递给 LOAD_CONST 操作码,则该值不能放入单个字节中,因此使用 EXTENDED_ARG 操作码。此值的二进制表示形式为 0b101000001 ,因此实际的操作码 (LOAD_CONST) 将第一个字节 (1000001) 作为参数 (十进制65),而 EXTENDED_ARG 操作码将下一个字节 (1) 作为参数,因此我们具有(144, 1), (100, 65) 作为输出的指令序列。
dis 模块的文档包含有关虚拟机当前实现的所有操作码的完整列表和说明。
5.2 Code Objects within other code objects
另一个值得关注的代码块代码对象是正在编译的模块。假设我们正在编译一个带有 fizzbuzz 函数作为内容的模块,那么输出将是什么样?为了找出答案,我们使用 python 中的 compile 函数来编译模块,其内容如 list 5.9 所示。
Listing 5.9: Nested function to illustrated nested code objects
1 | def f(): |
编译模块代码块后,我们得到如 list 5.10 所示的输出。
Listing 5.10: Bytecode instruction disassembly for listing 5.10
1 | 0 LOAD_CONST 0 (<code object f at 0x102a028a0, file "fizzbuzz.py",\ |
字节偏移量为 0 的指令加载了一个代码对象,该对象存储名称为 f :我们函数定义使用了 MAKE_FUNCTION 指令。list 5.11 显示了此代码对象的内容。
Listing 5.11: Bytecode instruction disassembly for nested function from listing 5.9
1 | co_argcount = 0 |
就像在模块中预期的那样,与代码对象参数相关的字段全为 0: (co_argcount, co_kwonlyargcount) 。如 list 5.10 所示,co_code 字段包含了字节码指令。co_consts 字段是一个有趣的字段。字段中的常量是代码对象,名称为: f 和 None。代码对象是函数的对象,值 “f” 是函数的名称,“None” 是函数的返回值。回想一下,python 编译器向没有返回值的代码对象添加了 “return None” 语句。
需要注意的是,在模块编译期间实际上并未创建函数对象。我们所拥有的只是代码对象:函数实际上是在代码对象执行期间创建的,如 list 5.10 所示。检查代码对象的属性表明它也是由其他代码对象组成的,如 list 5.12 所示。
Listing 5.12: Bytecode instruction disassembly for nested function from listing 5.10
1 | co_argcount = 0 |
前面的解释在这里也适用,仅在执行代码对象期间创建函数对象。
5.3 Code Objects in the VM
VM 中代码对象的实现和对象属性在 python 中的实现非常相似。与大多数内置类型一样,有一些代码类型为代码对象实例定义了代码对象类型和 PyCodeObject 结构。代码类型与前面各节中讨论的其他类型对象相似,因此不再赘述。代码对象的实例如 list 5.13 中的结构所示。
Listing 5.13: Code object implementation in C
1 | typedef struct { |
除了 co_stacksize,co_flags,co_cell2arg,co_zombieframe,co_weakreflist 和 co_extra 这些字段外,其与字段几乎都与 python 代码对象中的字段相同。因此,co_weakreflist 和 co_extra 并不是什么特殊的字段。这里的其余字段几乎具有与代码对象中相同的目的。 co_zombieframe 是为优化目的而存在的字段。这保留了对以前用作执行代码对象上下文的 frame 对象的引用。当这样的代码对象被重新执行时,它被用作执行 frame ,以减少另一个 frame 对象分配内存的开销。
6. Frames Objects
代码对象包含可执行的字节码,但缺少执行此类代码所需的上下文信息。以 list 6.0 中的一组字节码指令为例,LOAD_COST 将索引作为参数,但是代码对象没有数组或者从索引处加载值的数据结构,
Listing 6.0: A set of bytecode instructions
1 | 0 LOAD_CONST 0 (<code object f at 0x102a028a0, file "fizzbuzz.py",\ |
提供此类上下文信息的另一种数据结构是执行代码对象所必需的,而这正是 frame 对象所在的地方。人们可以将 frame 对象视为执行代码对象的容器:它了解代码对象,并且引用了执行某些代码对象期间所需的数据和值。像通常一样,python 确实为我们提供了一些函数用来检查 frame 对象,如 list 6.1 中使用的 sys._getframe() 函数。
Listing 6.1: Accessing frame objects
1 | import sys |
在代码对象可以被执行之前,必须创建一个 frame 对象,然后在 frame 对象中执行该代码对象。这样的 frame 对象包含可执行代码对象 (局部,全局和内置) 所需的所有命名空间,对当前执行线程的引用,用于执行 (evaluating) 字节码的堆栈以及对于可执行字节码来说其它的重要内部信息。为了更好地认识 frame 对象,我们可以看一下 Include/frame.h (此结构体实际在 Include/frameobject.h 中) 模块中 frame 对象数据结构的定义,如 list 6.2 所示。
Listing 6.2: Frame object definition in the vm
1 | typedef struct _frame { |
frame 中的字段以及文档不难理解,但我们提供了更多有关这些字段以及它们与字节码执行之间关系的细节。
f_back:这个字段是在当前代码对象之前执行的代码对象的 frame 的引用。给定一组 frame 对象,这些 frame 的 f_back 字段一起形成一个 stack of frames ,最终返回至 initial frame 。然后,此 initial frame 在的 f_back 字段的值为 NULL 。这种隐式的 stack of frames 形成了被我们称为调用栈 (call stack) 的东西。
f_code:此字段是对代码对象的引用。此代码对象包含了字节码 (bytecode) ,这些字节码在此 frame 的上下文中执行。
f_builtins:这是对内置命名空间的引用。该名称空间包含诸如 print,enumerate 等的名称及其对应的值。
f_globals:这是对代码对象的全局命名空间的引用。
f_locals:这是对代码对象的局部命名空间的引用。如前所述,这些名称会在函数作用域内定义。当我们讨论 f_localplus 字段时,我们会看到 python 在使用局部定义的名称时所做的优化。
f_valuestack:这是对 frame 执行栈 (evaluation stack) 的引用。回想一下,Python 虚拟机是基于堆栈的虚拟机,因此在字节码执行 (evaluation) 期间,将从堆栈的顶部读取值,并将字节码执行 (evaluation) 的结果存储在堆栈的顶部。该字段是在代码对象执行期间使用的堆栈。 frame 中的代码对象的堆栈大小 (stacksize) 提供了此数据结构可以扩展的最大深度。
f_stacktop:顾名思义,该字段指向执行栈 (evaluation stack) 的下一个空闲的 slot 。创建一个新的 frame 时,该值会被设置为 value stack:这是堆栈上的第一个可用空间,此时堆栈上没有任何东西 (items) 。
f_trace:此字段引用一个函数,该函数用于追踪 python 代码的执行。
f_exc_type,f_exc_value,f_exc_traceback,f_gen:是用于记录 (book keeping) 的字段,以便能够干净地执行生成器代码。之后我们会对 python 生成器进行更多的讨论。
f_localplus:这是对数组的引用,该数组包含足够的空间来存储单元和局部 (cell and local) 变量。该字段为执行循环 (evaluation loop) 提供了一种机制,该机制可使用 LOAD_FAST 和 STORE_FAST 指令来优化变量与 name stack 之间的加载和存储。 LOAD_FAST 和 STORE_FAST 操作码比相应的 LOAD_NAME 和 STORE_NAME 操作码提供更快的访问,因为它们使用数组索引访问变量的值,并且此操作基本上会在恒定的时间内完成,不像对应的操作码那样,会搜索映射中与给定名称相关联的值。当我们讨论执行循环 (evaluation loop) 时,我们将会看到在 frame 建立过程中是如何设置此值的。
f_blockstack:此字段是一个充当栈的数据结构的引用,该栈用于处理循环和异常处理。除了对虚拟机最重要的值堆栈 (value stack) 外,这是第二个堆栈,但这没有得到相应的重视。块堆栈 (block stack) ,异常和循环结构之间的关系非常复杂,我们将会在接下来的章节中对这个堆栈进行介绍。
6.1 Allocating Frame Objects
frame 对象在 python 代码执行 (evaluation) 期间无处不在,每个代码块被执行的时候都需要一个 frame 对象来提供一些上下文信息。通过调用 Objects/frameobject.c 模块中的 PyFrame_New 函数来创建新的 frame 对象。这个函数被调用了很多次 :每当一个代码对象被执行的时候,它都会被调用,减少调用这个函数开销的方法主要有两个,下面我们会简要的介绍一下这两个优化方法。
首先,代码对象具有一个 co_zombieframe 字段,该字段引用了一个惰性 frame 对象。当一个代码对象被执行的时候的时候,执行它的 frame 对象并不会立即被释放。该 frame 会被保留在 co_zombieframe 字段中,因此当下一个相同的代码对象被执行的时候,不需要花费时间为新的执行 frame 分配内存。 ob_type,ob_size,f_code,f_valuestack 字段会保留各自的值;f_locals,f_trace,f_exc_type,f_exc_value,f_exc_traceback,f_localplus 这些字段会保留分配的内存空间,但是局部变量的值会被清空。其余字段不保留对任何对象的引用。虚拟机使用的第二个优化方法是维护一个预分配 frame 对象的空闲列表 (free list) ,从这个空闲列表中可以获取 frame 用来执行代码对象。
frame 对象的源代码实际上是一个易读的,并且可以通过查看闭合的代码对象 (enclosed code object) 执行后如何重新分配已被分配的 frame 来了解 zombie frame 和自由列表 (free list) 的概念是如何实现的。list 6.3 中展示了重新分配 frame 的代码部分中有趣的部分。
Listing 6.3: Deallocating frame objects
1 | if (co->co_zombieframe == NULL) |
仔细观察发现,只有在进行递归调用时,即代码对象试图执行自身时,自由列表才会增长,因为仅在这个时间zombieframe 字段为 NULL 。使用 freelist 的这种微小优化有助于在某种程度上消除此类递归调用重复分配的内存。
本章不涉及与 frame 对象紧密相关的执行循环 (evaluation loop),而是涵盖了 frame 对象的要点。虽然我们在上面的讨论中仍然遗漏了一些内容,但我们会在后续章节中对这些进行介绍。例如,
- 当代码执行击中 return 语句时,值如何从一个 frame 传递到下一个 frame ?
- 线程状态是什么,线程状态从何而来?
- 当在执行 frame 中引发异常时,异常如何在 frame 栈中冒泡?等等。
我们在下一章中会介绍非常重要的解释器和线程状态数据结构,然后在后续各章中讨论执行循环 (evaluation loop),在之后的讨论期间,上面这些问题将会得到解答。
7. Interpreter and Thread States
如前所述,在 python 解释器初始化的过程中,其中的一个步骤就是解释器状态和线程状态数据结构的初始化。在本章中,我们将会详细研究这些数据结构并解释这些数据结构的重要性。
7.1 The Interpreter state
pylifecycle.c 模块中的 Py_Initialize 函数是在初始化 python 解释器时调用的函数之一。该函数处理 python 运行时的创建以及解释器状态和线程状态数据结构的初始化等。
解释器状态是一个非常简单的数据结构,它捕获由 python 进程中的一系列协作执行线程共享的全局状态。list 7.0 中提供了此数据结构定义中的代码片段,从而进一步了解这个重要的数据结构。
Listing 7.0: Cross-section of the interpreter state data structure
1 | typedef struct _is { |
只有熟悉目前为止所有章节内容并且使用了很长时间 python 的人,才可能对 list 7.0 中显示的字段感到熟悉。下面我们再次对解释器状态数据结构中的一些字段进行讨论。
- *next:单个 OS 进程中运行的 Python 可执行程序可以有多个解释器状态。这个 *next 字段引用 python 进程中的另一个解释器状态数据结构 (如果存在的话) ,它们形成了一个解释器状态的链表,如图 7.0 所示。每个解释器状态都有它自己的一组变量,这些变量会被引用该解释器状态的执行线程所使用。但是,该进程中的所有解释器线程共享该进程可用的内存和全局解释器锁 (Global Interpreter Lock) 。
- *tstate_head:此字段引用当前正在执行的线程的线程状态,或者在多线程的情况下,引用当前持有全局解释器锁 (GIL) 的线程。这是一个映射到
executin正在执行的 (executing) 操作系统线程的数据结构。
其余字段是由解释器状态的所有协作线程 (cooperating threads) 共享的变量。modules 字段是已安装的python 模块的表,稍后我们将看到:在讨论 import system 以及 builtins 字段是内置 sys 模块的引用时,解释器是如何找到这些模块的。该模块的内容是 len,enumerate 等内置函数的集合,而 Python/bltinmodule.c 模块包含此模块大部分内容的实现。 importlib 是一个引用 import 机制实现的字段,当我们详细讨论 import system 的时候,我们会说明更多的内容。 *codec_search_path,*codec_search_cache,*codec_error_registry,*codecs_initialized 和 *fscodec_initialized 是 python 用来编码和解码字节和文本的编解码相关的字段。这些字段的值用于查找此类编解码器以及处理可能与使用此类编解码器相关的错误。一个正在执行的 python 程序由一个或多个执行线程组成。解释器必须为每个执行线程维护一组状态,并且能够通过为每个执行线程维护一个线程状态数据结构来做到上面说的这些。下面我们看一下这个数据结构。
7.2 The Thread state
直接查看 list 7.1 中所示的线程状态数据结构,我们可以看到线程状态数据结构是比解释器状态数据结构更复杂的数据结构。
Listing 7.2: Cross-section of the thread state data structure
1 | typedef struct _ts { |
线程状态数据结构的下一个和上一个字段的引用是在给定线程状态之前和之后创建的线程状态。这些字段形成一个由线程状态组成的双向链表,这些线程状态共享一个解释器状态。 interp 字段是线程状态所属的解释器状态的引用。该 frame 字段引用当前的执行 frame ;当执行的代码对象更改时,此字段引用的值也会更改。
顾名思义,recursion_depth 指定了在递归调用期间 frame 栈应达到的深度。堆栈溢出时设置溢出标志,堆栈溢出后,线程允许再执行 50 次调用来启用某些清理操作。 recursion_critical 标志用于向线程发送信号,表明正在执行的代码不应溢出。 tracing 和 use_tracing 标志与用于跟踪线程执行的功能有关。就像在后续章节中将看到的那样, *curexc_type,*currexc_value,*curexc_traceback,*exc_type,*exc_value 和 *curexc_traceback 是在异常处理过程中使用的字段。
理解线程状态和实际线程之间的区别很重要。线程状态只是一个数据结构,它封装了正在执行的线程的某些状态。在运行的 python 进程中,每个线程状态都与本机 OS 线程相关联。图 7.1 说明了这种关系。我们可以清楚地看到,单个 python 进程是至少是一个解释器状态的宿主,而每个解释器状态是一个或多个线程状态的宿主,并且这些线程状态都映射到操作系统的执行线程。
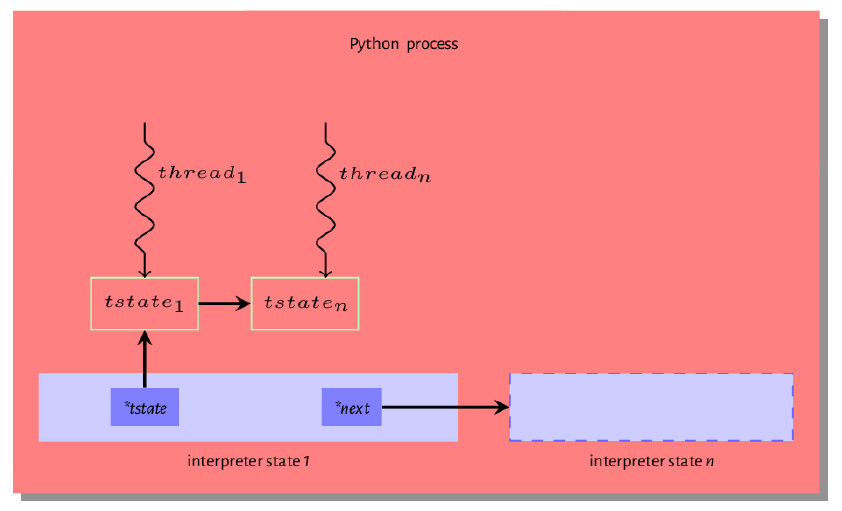
Figure 7.1: Relationship between interpreter state and thread states
操作系统线程和相关的 python 线程状态是在解释器初始化期间或由线程模块调用时创建的。即使在 python 进程中存在多个线程,但在任何给定时间点上,只有一个线程可以主动执行 CPU 绑定的任务。这是因为执行线程必须持有 GIL 才能在 python 虚拟机中执行字节码。如果不了解臭名昭著的 GIL 的概念,本章的内容将不够完整,因此我们将在下面继续对 GIL 进行介绍。
Global Interpreter Lock - GIL
尽管 python 线程是操作系统线程,但是除非该线程持有GIL,否则该线程是无法执行 python 字节码的。操作系统可能会调度一个不运行 GIL 的线程,但是正如我们看到的那样,此类线程实际上可以做的就是等待获取 GIL ,并且只有当它持有 GIL 时,它才能执行字节码。下面我们来看一下整个过程。
The Need for a GIL
在开始对 GIL 进行任何讨论之前,有一个问题值得讨论,为什么我们需要一个可能对线程产生不利影响的全局锁?有很多原因都说明了 GIL 是很重要的。但是,首先最重要的是要了解到 GIL 是 CPython 的实现细节,而不是实际的语言细节,在 Java 虚拟机上实现的 python,Jython 就没有 GIL 的概念。 GIL 存在的主要原因就是为了简化 CPython 虚拟机的实现。实现单个全局锁比实现细粒度锁要容易得多,而且核心开发人员也选择这样去做。但是,已经有一些项目在 python 虚拟机中实现细粒度的锁,但是这些项目有时会减慢单线程程序的速度。执行某些任务时,全局锁还提供了非常需要的同步功能。CPython 用于内存管理的是引用计数机制,如果没有 GIL 的概念,则可能使两个线程交错引用计数的增加和减少,从而导致内存处理方面严重的问题。使用全局锁的另一个原因是,CPython 调用的某些 C 库本来就不是线程安全的,因此在使用它们时候需要某种同步。
在解释器启动时,将创建一个执行的主线程,并且由于没有其他线程,因此 GIL 没有争用,因此主线程不会费心去获取锁。当使用 python 线程模块生成另一个线程时,GIL 就会开始起作用。list 7.3 中的代码片段来自Modules/_threadmodule.c,它提供了有关在创建新线程时该进程该如何处理的方法。
Listing 7.3: Cross-section of code for creating new thread
1 | boot->interp = PyThreadState_GET()->interp; |
list 7.3 中的代码片段来自 thread_PyThread_start_new_thread 函数,该函数被调用以创建新的线程。 boot 是一个数据结构,其中包含新线程需要执行的所有信息。 _PyThreadState_Prealloc 函数被调用为尚未创建的线程创建新的线程状态。在实际创建线程之前,执行主线程必须去获取 GIL;调用 PyEval_InitThreads 即可解决这个问题。现在解释器中线程被唤醒,并且主线程持有 GIL ,PyThread_start_new_thread 将会被调用来创建新的操作系统线程。当生成新的线程的时候,会把该线程在活动时应调用的函数传递给该线程。在这种情况下,这个需要被调用的函数是 Modules/_threadmodule.c 模块中的 _tbootstrap 函数。list 7.4 展示了这个函数的片段。
Listing 7.4: Cross-section of thread bootstrapping function
1 | static void t_bootstrap(void *boot_raw){ |
注意 list 7.4 中对 PyEval_AcquireThread 函数的调用。 PyEval_AcquireThread 函数是在 Python/ceval.c 模块中定义的,它调用 take_gil 函数,后者是试图获取 GIL 的实际函数。以下的文本中引用了源文件中提供的有关此过程的说明。
GIL 只是一个布尔变量 (gil_locked),其访问受互斥锁保护 (gil_mutex),其更改是由条件变量 (gil_cond) 发出信号。 gil_mutex 的使用时间很短,因此几乎没有竞争。在 GIL-holding 线程中,主循环 (PyEval_EvalFrameEx) 必须能够根据另一个线程的需要释放 GIL 。因此使用一个易变的布尔变量 (gil_drop_request),该变量在每次执行循环时都会检查。在 gil_cond 上等待微秒级别的间隔后,该变量将会被重置。[实际上,使用另一个可变布尔变量 (eval_breaker) ,将多个条件合并为一个条件。可变布尔值足以作为线程间信号传递的手段,因为 Python 仅在高速缓存一致性体系结构上运行。] 想要获取 GIL 的线程首先需要在设置 gil_drop_request 之前让其经过给定的时间 (微秒级别的间隔) 。这鼓励一定周期后进行切换,但是由于操作码可能花费任意时间执行,因此不强制执行。用户可以使用 Python API 中的 sys.getswitchinterval() 和 sys.setswitchinterval() 这两个方法来读取和修改时间间隔值。当一个线程释放 GIL 并设置了 gil_drop_request 时,该线程将确保安排另外一个等待 GIL 的线程。它通过等待一个条件变量 (switch_cond) 直到 gil_last_holder 的值更改为自己的线程状态指针以外的值来表明另一个线程能够使用 GIL。这意味着要禁止多核计算机上等待时间的有害行为,在多核计算机上,一个线程会随机性的释放 GIL,但仍在运行并最终成为第一个重新获取 GIL 的对象,这使得 ”时间片“ 比预期的长得多。
以上对于新产生的线程意味着什么?list 7.4 中的 t_bootstrap 函数调用 PyEval_AcquireThread 函数,该函数处理对 GIL 的请求。因此,对发出此请求时会发生什么情况的一般解释是,假设 A 是持有 GIL 的执行主线程,而 B 是正在产生的新线程。
- 生成 B 时,将调用 take_gil 。这将检查是否设置了条件变量 gil_cond。如果未设置,则线程开始等待。
- 等待时间过后,将设置 gil_drop_request。
- 在执行循环 (evaluation loop) 上执行的线程 A 检查循环的每次迭代是否设置了 gil_drop_request 变量。
- 线程 A 在检测到已设置 gil_drop_request 变量时删除 GIL,然后还设置了 gil_cond 变量。
- 线程 A 还等待另一个变量 switch_cond,直到 gil_last_holder 的值设置为除线程 A 的线程状态指针以外的值,该值指示另一个线程已采用 GIL 。
- 线程 B 现在具有 GIL ,可以继续执行字节码。
- 线程 A 等待给定时间,设置 gil_drop_request ,然后循环继续。
GIL and Performance
GIL 就是为什么大多数情况下,在 python 中增加在一个 CPU 上的绑定程序的单个进程中的工作线程数量通常不会加快此类程序的主要原因。实际上,与单线程程序相比,添加线程有时会对程序的性能产生不利影响。这与所有切换和等待相关的成本有关。
总结本章的内容,我们回顾了到目前为止在 python 虚拟机上创建的模型。当 python 可执行文件是包含某些有效源码内容的文件时,首先会初始化解释器和线程状态,然后将源文件编译为代码对象。然后将代码对象传递到解释器循环模块,在该模块中,为了执行代码对象,创建了一个 frame 对象并将其附加到执行的主线程中。因此,我们有一个 python 进程,该进程可能包含一个或多个解释器状态,并且每个解释器状态可能具有一个或多个线程状态,并且每个线程状态都引用了一个 frame ,该 frame 可以引用另一个 frame ,依此类推,形成一个 frame 堆栈。图7.2 展示了此顺序。
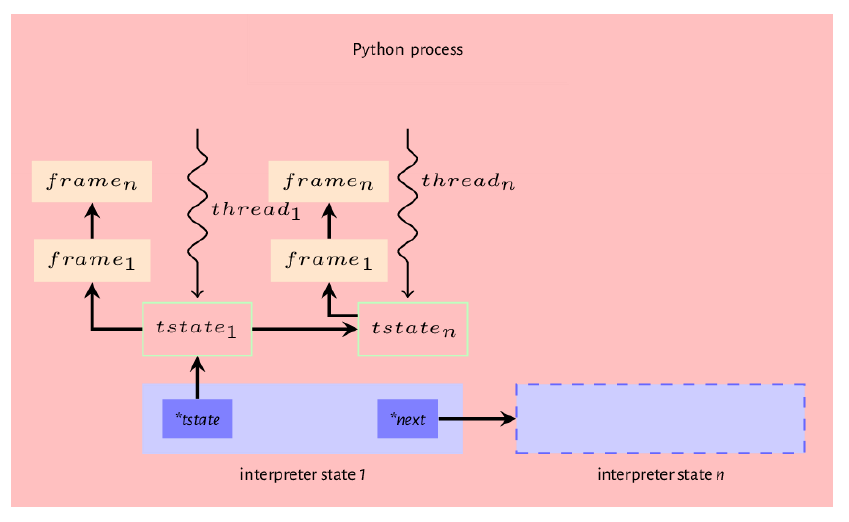
Figure 7.2: Interpreter state, thread state and frame relationship
在下一章中,我们将展示我们所描述的所有部分如何实现 python 代码对象执行的。
8. Intermezzo: The abstract.c Module
到目前为止,我们已经多次提到 python 虚拟机通常将执行的值 (values for evaluation) 视为 PyObjects。这就留下了一个明显的问题:如何在此类通用对象上安全地执行操作?例如,当执行 (evaluating) 字节码指令 BINARY_ADD 时,会从执行堆栈中弹出两个 PyObject 值,并将其用作加法运算的参数,但是虚拟机如何知道这些值是否实际实现了加法运算所属的协议?
要了解 PyObjects 上的许多操作是如何工作,我们只需要查看 Objects/Abstract.c 模块。该模块定义了许多对实现给定对象协议的对象起作用的函数。这意味着,例如,如果一个对象要加上两个对象,则此模块中的 add 函数将期望两个对象都实现 tp_numbers slots 的 add 方法。解释这个问题的最佳方法是举例说明。
考虑 BINARY_ADD 操作码的情况,当将它应用于两个数字的加法运算时,将调用 Objects/Abstract.c 模块的 PyNumber_Add 函数。list 8.1 中提供了此功能的定义。
Listing 8.1: Generic add function from abstract.c module
1 | PyObject * PyNumber_Add(PyObject *v, PyObject *w){ |
list 8.1 中 PyNumber_Add 函数的第 2 行对 binary_op1 函数的调用十分有趣。 binary_op1 函数是另一个通用函数,该函数的参数中包扩两个数值类型或数值类型的子类,并将一个二进制函数应用于这两个值。 NB_SLOT 宏将给定方法的偏移量返回到 PyNumberMethods 结构中;回想一下,此结构是处理数值方法的集合。list 8.2 中包含此类 binary_op1 函数的定义,下面的是对该函数的深入说明。
Listing 8.2: The generic binary_op1 function
1 | static PyObject * binary_op1(PyObject *v, PyObject *w, const int op_slot){ |
该函数接受三个值,两个 PyObject *v 和 *w 以及一个整数 operation slot,它是在 PyNumberMethods 结构中的偏移量。
第 3 行和第 4 行定义了两个值 slotv 和 slotw ,它们是表示其类型所建议的二进制函数的结构。
从第 3 行到第 13 行,我们尝试对 v 和 w 取消对 op_slot 参数给出的函数的引用。在第 8 行,会检查两个值是否具有相同的类型,如果两个值具有相同的类型,则不需要取消在 op_slot 中对第二个值的函数的引用。即便两个值不是同一类型,但只要从两个值取消引用的函数是相等的,那么 slotw 值就被清空。
取消引用二进制函数后,如果 slotv 不为 NULL,然后在会第 15 行中,检查 slotw 是否也为 NULL,并且 w 的类型是否是 v 的子类型,如果上面的结果为 true,则 v 和 w会被应用到 slotw 函数中。发生这种情况的原因就是继承之后的方法就是我们想要使用的方法。如果 w 不是子类型,则会在第 22 行将 slotv 应用于这两个值。
到达第 27 行意味着 slotv 函数为 NULL,因此 slotw 只要不为 NULL,那么我们就对 v 和 w 应用 slotw 引用。
如果 slotv 和 slotw 都不包含函数,则返回 Py_NotImplemented。 Py_RETURN_NOTIMPLEMENTED 只是一个宏,该宏会在返回 Py_NotImplemented 值之前增加其引用计数。
上面给出的解释的想法是,虚拟机如何能对提供给它的值执行对应操作的蓝图。我们在这里通过忽略可以重载的操作码来简化一些事情,例如 + 符号映射到 BINARY_ADD 操作码,并且可以应用于字符串,数字或序列,但是在上面的示例中,我们只看了适用于数字和数字子类。很难想象如何处理重载操作。在 BINARY_ADD 的情况下,如果查看 PyNumber_Add 函数,则可以看到,如果从 binary_op1 调用返回的值是 Py_NotImplemented,则虚拟机将尝试将这些值视为序列,并尝试取消引用序列连接的方法,然后将它们应用于两个值 (如果它们实现了序列协议) 。回到 ceval.c 中的解释器循环 (interpeter loop) ,当我们看到对 BINARY_ADD 操作码进行执行 (evaluation) 的情况时,我们会看到以下代码段。
Listing 8.3: ceval implementation of binary add
1 | PyObject *right = POP(); |
在讨论解释器循环时,请忽略第 1 行和第 2 行。从其余片段中我们看到的是,当我们遇到 BINARY_ADD 时,调用的第一个操作是检查两个值是否是字符串,以便将字符串连接方法应用于这些值上。如果不是字符串,则将 Objects/Abstract.c 中的 PyNumber_Add 函数应用于这两个值。尽管代码在 Python/ceval.c 中完成的字符串检查以及在 Objects/Abstract.c 中完成的数字和序列检查看起来似乎有些混乱,但是很明显,当我们有一个重载的操作码时,会发生什么。
上面提供的解释是大多数操作码操作的处理方式:检查要计算的值的类型,然后根据需要取消引用该方法并应用于参数值。
9. The evaluation loop, ceval.c
我们终于到了虚拟机的核心部分:在这里,虚拟机遍历代码对象的 python 字节码指令并执行此类指令。这是通过使用一个 for 循环来实现的,该循环遍历每种类型上的操作码切换以运行所需的执行代码。。 Python/ceval.c 模块约有 5411行,实现了所需的大多数功能:此模块的核心是 PyEval_EvalFrameEx 函数,该函数约 3000 行,其中包含实际的执行循环 (evaluation loop) 。 PyEval_EvalFrameEx 函数是本章重点研究的重点。
Python/ceval.c 模块提供了特定于平台的优化,例如 threaded gotos,以及 python 虚拟机优化,例如 opcode 预测。在本文中,我们更加关注虚拟机的流程和优化,因此我们可以忽略此处介绍的任何特定于平台的优化流程,只要它不超出我们对执行循环 (evaluation loop) 的解释即可。在这里,我们会进行比平时更详细地介绍,以便于对虚拟机的核心结构和工作方式提供可靠的解释。值得注意的是,操作码及其实现始终在不断变化,因此这里的描述可能会不太准确。
在执行字节码之前,必须执行许多内部操作,例如创建和初始化 frames ,设置变量以及初始化虚拟机变量 (例如指令指针) 。我们首先需要了解这些操作,然后在执行 (evaluation) 开始前必须对进程进行设置。
9.1 Putting names in place
如上所述,虚拟机的核心是 PyEval_EvalFrameEx 函数,该函数实际执行 python 字节码,但是在执行该字节码之前,必须进行许多设置以进行准备执行 (evaluation) 的上下文,如错误检查,帧创建和初始化等。这也是 Python/ceval.c 模块中 _PyEval_EvalCodeWithName 函数出现的地方。为了解释这些,我们假定我们正在用 list 9.0 中所示的模块内容。
Listing 9.0: Content of a simple module
1 | def test(arg, defarg="test", *args, defkwd=2, **kwd): |
回想一下为代码块创建的代码对象;这些代码块可以是函数,模块等,因此对于具有上述内容的模块,我们可以安全地假设我们正在处理两个代码对象,一个用于模块,一个用于模块内定义的功能测试。
list 9.0 中的模块生成代码对象后,通过 Python/pythonrun.c 模块中函数调用链的执行来生成代码对象:run_mod -> PyEval_EvalCode -> PyEval_EvalCodeEx -> _ PyEval_EvalCodeWithName -> PyEval_EvalFrameEx 。目前,我们关注的是 _PyEval_EvalCodeWithName 函数,该函数具有 list 9.1 中所示的特征。此函数处理在 PyEval_EvalFrameEx 中的字节码执行 (evaluation) 之前所需的名称设置。但是,如 list 9.1 所示,通过查看 _PyEval_EvalCodeWithName 的函数特征,有人可能会问为什么这个函数与执行的模块对象相关而不是与实际函数有关。
Listing 9.1: _PyEval_EvalCodeWithName function signature
1 | static PyObject * _PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals, PyObject **args, int argcount, PyObject **kws, int kwcount, |
为了解决这个问题,人们必须更多地思考代码块和代码对象,而不是函数或者模块。代码块可以具有_PyEval_EvalCodeWithName 函数特征中指定的任何参数,也可以不包含任何参数:函数恰好是代码块的一种更特定的类型,它提供了大多数的这些值。这意味着为模块代码对象执行 _PyEval_EvalCodeWithName 的情况不是很有趣,因为其中大多数参数都没有值。通过 CALL_FUNCTION 操作码进行 python 函数调用时,会发生一些有趣的情况。这也会导致在 Python/ceval.c 模块中也会调用 fast_function 函数。该函数从函数对象中提取函数参数,然后使用 _PyEval_EvalCodeWithName 函数执行所有必要的健全性检查 (sanity checks) 。
_PyEval_EvalCodeWithName 是一个很大的函数,因此我们在此处不讨论它,但是它的大多数设置过程都非常简单。例如,回想一下我们提到的, frame 对象的 fastlocals 字段为局部命名空间提供了一些优化,并且非位置参数仅在运行时才完全知道;这基本上意味着,如果不进行仔细的错误检查,就无法填充 fastlocals 这个数据结构。因此,正是在通过 _PyEval_EvalCodeWithName 函数进行这个设置过程当中,一个 frame 的 fastlocals 字段所引用的数组才填充了全部的局部值。 _PyEval_EvalCodeWithName 调用时要进行的设置过程涉及的步骤如 list 9.1 中所示。
Listing 9.2: _PyEval_EvalCodeWithName setup steps
- 初始化为代码对象执行提供上下文的 frame 对象。
- 将关键字 *dict* 添加到快速局部 frame 中。
- 添加关键字参数到 `fastlocals` 中.
- 将非位置、非关键字参数的可变序列添加到`fastlocals`数组中 (示例模块中的 *args 参数) 。
这些值一起存储在一个元组数据结构中。 - 请检查提供给代码块的任何关键字参数是否为预期参数,并且没有提供两次。
- 检查缺少的位置参数,如果发现任何错误,则抛出错误。
- 将默认参数添加到 “fastlocals” 数组中 (在我们的示例模块中为 “defarg” ) 。
- 将关键字默认值添加到`fastlocals` (在我们的示例模块中为`defkwd` ) 。
- 初始化单元格变量的存储并将自由变量数组复制到框架中。
- 做一些生成器相关的内部工作:我们在讨论生成器时会更加详细地介绍这一点。
9.2 The parts of the machine
使用所有名称后,将使用 frame 对象作为其参数之一调用 PyEval_EvalFrameEx 函数。大致看一下该函数,发现该函数由相当多的 C 宏和变量组成。宏是执行循环 (execution loop) 中不可或缺的一部分:宏提供了一种抽象方法,可以抽象出重复的代码,而不会产生函数调用的开销,因此,我们会描述其中一部分宏。在本节中,我们假设虚拟机未运行 C 优化,例如启用 computed gotos ,因此我们可以忽略与此类优化相关的宏。我们从描述一些对执行循环 (evaluation loop) 执行至关重要的变量开始。
**stack_pointer: 引用执行帧的值堆栈中的下一个空闲插槽 (slot) .
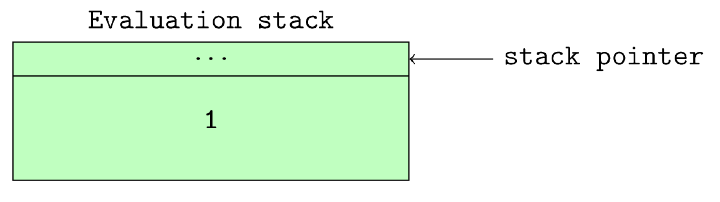
Figure 9.0: Stack pointer after a single value has been pushed onto the stack
*next_instr:是指执行循环 (evaluation loop) 要执行的下一条指令。可以将其视为虚拟机的程序计数器。 Python 3.6 将此值的类型更改为 2 个字节的无符号 short ,以处理新的字节码指令大小。
opcode:指当前正在执行的 python 操作码或将要执行的操作码。
oparg:引用当前正在执行的操作码或要接受参数的操作码。
why:评估循环是一个无限循环,由无限for循环:for (;;) 实现,因此循环需要一种机制来跳出循环并指定发生中断的原因。该值表示退出执行循环 (evaluation loop) 的原因。例如,如果代码块由于返回语句而退出循环,则此值将包含 WHY_RETURN 状态。
fastlocals:指局部定义名称的数组。
freevars:引用在代码块中使用但未在该代码块中定义的名称的列表。
retval:指执行代码块后的返回值。
co:引用包含将由执行循环 (evaluation loop) 执行的字节码的代码对象。
names:引用执行 frame 的代码块中所有值的名称。
consts:引用代码对象使用的常量。
Bytecode instruction
我们在代码对象一章中讨论了字节码指令的格式,但是它与我们的讨论非常相关,因此我们在这里重复对字节码指令格式的描述。假设我们正在使用 python 3.6 字节码,则所有字节码均为 16 位长。 Python VM 在我目前正在写这本书的机器上使用一点 endian 字节编码,因此 16 位代码的结构如下图所示,其中 opcode 占用 1 个字节,而 opcode 的参数占用第二个字节。
Bytecode instruction format showing opcode and oparg
提取操作码和参数涉及一些位操作,我们将在接下来的小节中看到。重要的是要注意,由于操作码现在是两个字节而不是一个字节,因此指令指针的操作属于指针操作。
以下宏在评估循环中起着非常重要的作用。
- TARGET (op) :扩展到 case op 语句。这会将当前操作码与实现该操作码的代码块进行匹配。
- DISPATCH:扩展以继续。它与下一个宏 FAST_DISPATCH 一起在执行操作码后处理执行循环 (evaluation loop) 的控制流。
- FAST_DISPATCH:扩展为跳转到执行 (evaluation) for 循环内的 fast_next_opcode 标签。
随着 Python 3.6 中标准的 2 字节操作码的引入,以下宏集用于处理代码访问。
- INSTR_OFFSET() :此宏将当前指令的字节偏移量提供给指令数组。这扩展为 (2 *(int)(next_instr - first_instr))。
- NEXTOPARG():这会将操作码和 oparg 变量更新为要执行的下一个字节码指令的操作码和参数的值。此宏扩展为以下代码段。
Listing 9.3: Expansion of the NEXTOPARG macro
1 | do { \ |
OPCODE 和 OPARG 宏处理用于提取操作码和参数的位操作。图 9.0 显示了字节码指令的结构,其中操作码的参数取低 8 位,操作码本身取高 8 位,因此 OPCODE 扩展为 ((word) & 255) ,从而从字节码指令中提取最高有效字节,同时扩展为 ((word) >> 8) 的 OPARG 提取最低有效字节。
- JUMPTO(x):此宏扩展为 (next_instr = first_instr + (x) / 2),并执行绝对跳转到字节码流中的特定偏移量。
- JUMPBY(x):此宏扩展为 (next_instr + =(x) / 2),并执行从当前指令偏移量到字节码指令流中另一点的相对跳转。
- PREDICT(op):此操作码与 PREDICTED(op) 操作码一起实现 python 执行循环 (evaluation loop) 操作码预测。该操作码扩展为以下代码段。
- PREDICTED(op):此宏扩展为 PRED _##op: 。
Listing 9.4: Expansion of the PREDICT(op) macro
1 | do{ \ |
上面定义的最后两个宏可处理操作码预测。当执行循环 (evaluation loop) 遇到 PREDICT(op) 宏时,解释器会假定要执行的下一条指令是 op 。宏会检查这是否确实有效,如果有效则获取实际的操作码和参数,然后跳转到标签 PRED_##op,其中 ## 是实际操作码的占位符。例如,如果我们遇到了诸如 PREDICT(LOAD_CONST) 之类的预测,则如果该预测有效,则 goto 语句参数将为 PRED_LOAD_CONSTop 。通过检查 PyEval_EvalFrameEx 函数的源代码,可以找到扩展到 PRED_LOAD_CONSTop 的 PREDICTED(LOAD_CONST) 标签,因此,在成功预测该指令后,将跳转至该标签,否则将继续正常执行。这种预测节省了 switch 语句额外遍历所涉及的成本,否则常规代码执行会发生这种情况。
我们关注的下一组宏是堆栈操作宏,用于处理 frame 对象的值栈 (value stack) 中的值的放置和提取。这些宏非常相似,下面的代码片段显示了一些示例。
- STACK_LEVEL():这将返回堆栈上的 items 数量。宏扩展为 ((int) (stack_pointer - f -> f_valuestack)) 。
- TOP():返回堆栈上的最后一项。这扩展为 (stack_pointer[-1]) 。
- SECOND():这将返回堆栈上的倒数第二个项目。这扩展为 (stack_pointer[-2]) 。
- BASIC_PUSH(v):这将 v 入栈。它扩展为 (* stack_pointer ++ =(v)) 。该宏的当前别名为 PUSH(v)。
- BASIC_POP():将栈顶元素出栈。这扩展为 (*–stack_pointer)。当前的别名是 POP()。
我们关心的最后一组宏是那些处理局部变量操作的宏。这些宏 GETLOCAL 和 SETLOCAL 用于在 fastlocals 数组中获取和设置值。
- GETLOCAL(i):这扩展为 (fastlocals[i]) 。这处理从局部数组中获取局部定义的名称。
- SETLOCAL(i,value):这将扩展为 list 9.5 中的代码段。此宏将局部数组的第 i 个元素设置为提供的值。
Listing 9.5: Expansion of the SETLOCAL(i, value) macro
1 | do { PyObject *tmp = GETLOCAL(i); \ |
UNWIND_BLOCK 和 UNWIND_EXCEPT_HANDLER 与异常处理相关,我们将在后续部分中对其进行介绍。
9.3 The Evaluation loop
我们终于来到了虚拟机的核心:实际执行 (evaluted) 操作码的循环。实际循环的实现是非常反常的,因为这里实际上没什么特别的,只是永无休止的 for 循环和用于匹配操作码的大量 switch 语句。为了获得对该语句的具体理解,我们看一下 list 9.6中 hello world 函数的执行。
Listing 9.6: Simple hello world python function
1 | def hello_world(): |
list 9.6 显示了list 9.7 中函数的反汇编,我们将展示这组字节码如何通过执行 (evaluation) 开关循环。
Listing 9.7: Disassembly of function in listing 9.6
1 | LOAD_GLOBAL 0 (0) |
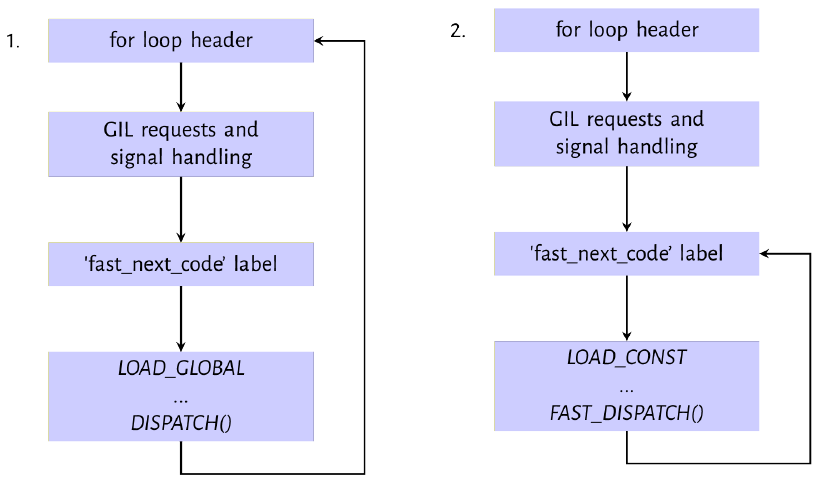
Figure 9.1: Evaluation path for LOAD_GLOBAL and LOAD_CONST instructions
图 9.1 显示了 LOAD_GLOBAL 和 LOAD_CONST 指令的执行 (evaluation) 路径。图 9.2 的两个图像中的第二个和第三个块表示在执行循环 (evaluation loop) 的每次迭代中执行的整理任务 (housekeeping tasks) 。在上一章的解释器和线程状态中讨论了 GIL 和信号处理检查,正是在这些检查期间,执行线程可能放弃对 GIL 的控制权,让另一个线程执行。 fast_next_opcode 是紧随 GIL 和信号处理代码之后的代码标签,当循环希望跳过先前的检查时,这些代码将作为跳转目标,就像我们在查看 LOAD_CONST 指令时所看到的那样。
第一条指令 LOAD_GLOBAL 由 switch 语句的 LOAD_GLOBAL case 语句执行 。像其他操作码一样,此操作码的实现是一系列 C 的语句和函数调用,如 list 9.8 所示。操作码的实现将全局或内置命名空间中由给定名称标识的值加载到执行堆栈中。 oparg 是元组的索引,其中包含代码块中使用的所有名称 co_names 。
Listing 9.8: LOAD_GLOBAL implementation
1 | PyObject *name = GETITEM(names, oparg); |
如果 LOAD_GLOBAL 操作码是 dict 对象,则 LOAD_GLOBAL 操作码的查找算法首先尝试从 f_globals 和 f_builtins 字段中加载名称,否则它将尝试从 f_globals 或 f_builtins 对象中获取与名称相关联的值,并假设它们实现了某种协议来获取与给定名称相关的值。如果找到该值,则使用 PUSH(v) 将该值加载到执行堆栈 (evaluation stack) 上,否则会报错,并且会跳转到错误代码标签以进行错误处理。如流程图所示,将此值压入执行堆栈 (evaluation stack) 后,将调用 DISPATCH() 宏,该宏是 Continue 语句的别名。
图 9.1 中标记为 2 的第二张图显示了 LOAD_CONST 的执行。list 9.9 是 LOAD_CONST 操作码的实现。
Listing 9.9: LOAD_CONST opcode implementation
1 | PyObject *value = GETITEM(consts, oparg); |
这将通过常规设置进行,即 LOAD_GLOBAL,但在执行后,将调用 FAST_DISPATCH() 而不是 DISPATCH() 。这将导致跳转到 fast_next_opcode 代码标签,在该标签处循环执行将继续跳过信号,并在下一次迭代时进行 GIL 检查。具有执行 C 函数调用的实现的操作码由 DISPATCH 宏组成,而诸如 LOAD_GLOBAL 之类的操作码在其实现中未进行 C 函数调用的操作码则使用 FAST_DISPATCH 宏。这意味着仅在执行执行 C 函数调用的操作码后才能放弃 GIL 。
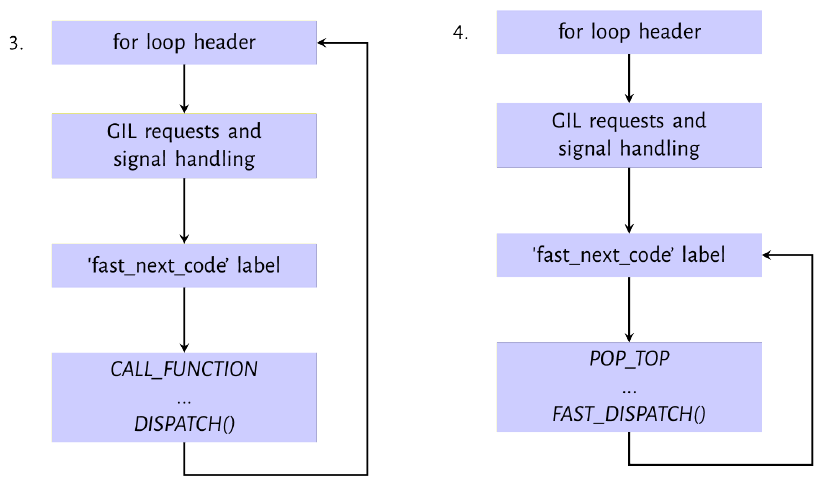
Figure 9.2: Evaluation path for CALL_FUNCTION and POP_TOP instruction
下一个执行的操作码是 CALL_FUNCTION 操作码,如图 9.2 中的第一张图所示。当仅在调用中使用位置参数进行函数调用时,编译器将发出此操作码。list 9.10 显示了此操作码的实现。操作码实现的核心是 call_function( &sp, oparg, NULL) 。 oparg 是传递给该函数的参数数量,而 call_function 函数从执行堆栈 (evaluation stack ) 中读取该数目的值。
Listing 9.10: CALL_FUNCTION opcode implementation
1 | PyObject **sp, *res; |
图 9.2 的图 4 中显示的下一条指令是 POP_TOP 指令,该指令从执行堆栈 (evaluation stack) 的顶部删除单个值,它清除了上一个函数调用放置在堆栈上的所有值。
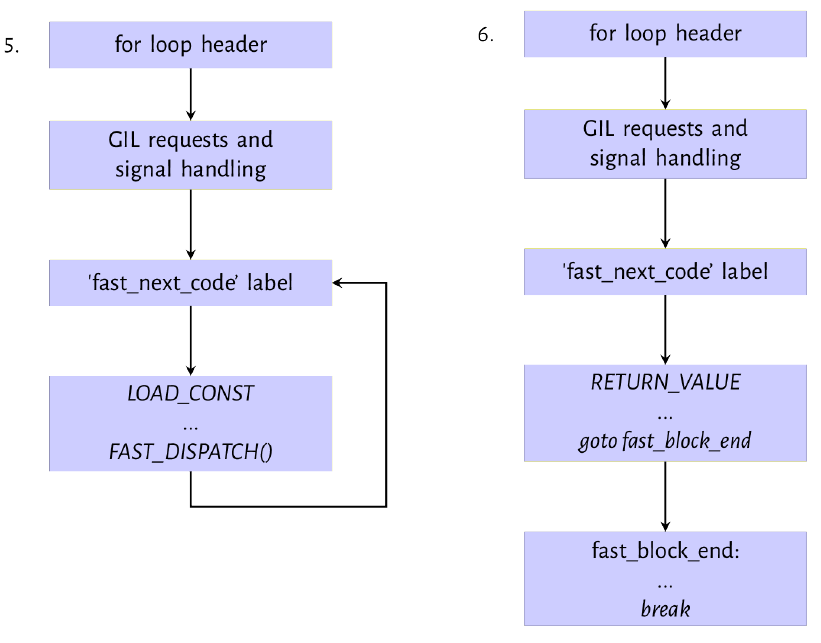
Figure 9.3: Evaluation path for LOAD_CONST and RETURN_VALUE instruction
下一组指令是图 9.3 的图 5 和图 6 中所示的 LOAD_CONST 和 RETURN_VALUE 。 LOAD_CONST 操作码将 None 值加载到执行堆栈 (evaluation stack) 上,以供 RETURN_VALUE 使用。当 python 函数未明确返回任何值时,这些总是在一起。我们已经研究了 LOAD_CONST 指令的机制。 RETURN_VALUE 指令将堆栈的顶部弹出到 retval 变量中,将 WHY 状态代码设置为 WHY_RETURN ,然后跳转到 fast_block_end 代码标签。从那里继续执行,退出 for 循环,然后将 retval 变量的值返回给调用函数。
请注意,我们查看的许多代码片段都有 goto error 跳转,但是到目前为止,我们刻意讨论了错误,排除了异常。我们将在下一章中讨论异常处理。尽管本节介绍的功能相当琐碎,但它在执行字节码指令时封装了执行循环 (evaluation loop) 的主要行为。任何其他操作码可能会有一些稍微复杂的实现,但是执行的本质与上述相同。
接下来,我们看一下 python 虚拟机支持的其他一些有趣的操作码。
9.4 A sampling of opcodes
python 虚拟机有大约 157 个操作码,因此我们随机选择一些操作码并进行解构,以更加了解这些操作码的功能。下面是这些操作码中的一部分:
- MAKE_FUNCTION:顾名思义,操作码根据执行堆栈 (evaluation stack) 上的值创建一个函数对象。思考一个包含 list 9.11 所示功能的模块。
Listing 9.11: Function definitions in a module
1 | def test_non_local(arg, *args, defarg="test", defkwd=2, **kwd): |
从已编译模块的代码对象反汇编可以得到 list 9.12 中所示的字节码指令集。
Listing 9.11: Disassembly of code object from listing 9.11
1 | 0 LOAD_CONST 8 (('test',)) |
我们可以看到,MAKE_FUNCTION 操作码在一系列字节码指令中出现了两次:模块中的每个函数定义各一次。 MAKE_FUNCTION 的实现创建了一个函数对象,然后使用函数定义的名称将函数存储在局部命名空间中。要注意,定义了默认参数后,会将默认参数压入堆栈。 MAKE_FUNCTION 的实现通过使用位掩码的 oparg (and’ing the oparg with a bitmask) 并从堆栈中弹出值来消耗这些值。
Listing 9.12: MAKE_FUNCTION opcode implementation
1 | TARGET(MAKE_FUNCTION) { |
上面的标志表示以下内容。
- 0x01:堆栈上按位置顺序排列的默认参数对象的元组。
- 0x02:堆栈上关键字参数默认值的字典。
- 0x04:堆栈上的一个注释字典。
- 0x08:堆栈上一个闭合的包含自由变量的元组。
实际上创建函数对象的 PyFunction_NewWithQualName 函数在 Objects/funcobject.c 模块中实现,其实现非常简单。该函数初始化一个函数对象并在该函数对象上设置值。
2.LOAD_ATTR:此操作码处理诸如 x.y 之类的属性引用。假设我们有一个实例对象 x ,则诸如 x.name 之类的属性引用将转换为 list 9.13 中所示的一系列操作码。
Listing 9.13: Opcodes for an attribute reference
1 | 24 LOAD_NAME 1 (x) |
LOAD_ATTR 操作码实现非常简单,如 list 9.14 所示。
Listing 9.14: LOAD_ATTR opcode implementation
1 | TARGET(LOAD_ATTR) { |
PyObject_GetAttr 函数是我们在对象一章中介绍的函数。任何在对象的 tp_getattro 属性中的值都会被该函数取消引用,并使用该函数将对象属性的值加载到值堆栈的顶部。
3.CALL_FUNCTION_KW:此操作码的功能与前面讨论的 CALL_FUNCTION 操作码非常相似,但用于带有关键字参数的函数调用。该操作码的实现在 list 9.15 中。请注意,CALL_FUNCTION 操作码实现的主要变化之一是:当调用 call_function 时,names组成的元组 (a tuple of names) 现在会作为参数之一进行传递。
Listing 9.15: CALL_FUNCTION_KW opcode implementation
1 | PyObject **sp, *res, *names; |
名称是函数调用的关键字参数,它们在 _PyEval_EvalCodeWithName 中用于在执行函数的代码对象之前初始化操作。
这限制了我们对执行循环 (evaluation loop) 的解释。正如我们看到的那样,执行循环 (evaluation loop) 背后的概念并不复杂:每个操作码都是用 C 进行定义和实现,这些实现就是实际的功能。我们没有涉及的一个非常重要的区域就是异常处理和块堆栈,这是我们在下一章中将会看到的两个紧密相关的概念。
10. The Block Stack
没有获得应有关注的数据结构之一就是块堆栈 (block stack) ,它是 frame 对象内的另一个堆栈。Python VM 的大多数讨论都只是顺带提及了块堆栈,然后就会将重点放在执行堆栈 (evaluation stack) 上。但是,块堆栈非常重要:可能还有其他方法可以实现异常处理,但是正如我们在本章学习的过程中所看到的那样,使用块堆栈会使实现异常处理变得异常简单。块堆栈和异常处理交织在一起,以至于如果不思考异常处理,就不会完全理解块堆栈重要性。块堆栈也用于循环,但是很难弄清带有循环的块堆栈,直到人们研究了诸如 break 之类的循环结构如何与异常处理程序交互时,才让我们直接了解细节。块堆栈使这种交互的实现变得简单。
块堆栈是 frame 对象内的堆栈数据结构字段。就像 frame 的执行堆栈 (evaluation loop) 一样,在执行 frame 的代码期间,会将值压入块堆栈并从中弹出。但是,块堆栈仅用于处理循环和异常。解释块堆栈的最好方法是举一个例子,因此我们用一个简单的 try … finally 构造一个循环,如 list10.0 所示。
Listing 10.0: Simple python function with exception handling
1 | def test(): |
当 list10.0 中的函数被分解时,其结果如 lsit 10.1 所示。
Listing 10.1: Disassembly of function in listing 10.0
1 | 2 0 SETUP_LOOP 34 (to 36) |
对于一个简单的函数,list 10.1 有很多操作码,但这是由于 for 循环和 try .. finally 构造的结合导致的。这里重点的操作码是 SETUP_LOOP 和 SETUP_FINALLY 操作码,因此我们看一下它们的实现,以了解其工作的要旨 (所有 SETUP_* 操作码都映射到相同的实现) 。
SETUP_LOOP 操作码的实现是一个简单的函数调用:PyFrame_BlockSetup( f, opcode, INSTR_OFFSET() + oparg, STACK_LEVEL()); 参数是很容易解释的:f 是 frame,opcode 是当前正在执行的操作码,INSTR_OFFSET() + oparg 是该块之后的下一条指令的指令增量 (对于上面的代码,SETUP_LOOP 的增量为 50),并且 STACK_LEVEL 表示该 frame 的值堆栈上有多少个 items 。函数调用将创建一个新块并将其压入块堆栈。该块中包含的信息足以使虚拟机在该块中发生某些情况时继续执行。list 10.2 展示了此函数的实现。
Listing 10.2: Block setup code
1 | void PyFrame_BlockSetup(PyFrameObject *f, int type, int handler, int level){ |
list 10.2 中的处理程序是指向 SETUP_ * 块之后应执行的下一条指令的指针。最好从上方用图形表示执行过程来说明,而图 10.0 则用一部分字节码说明该示例。
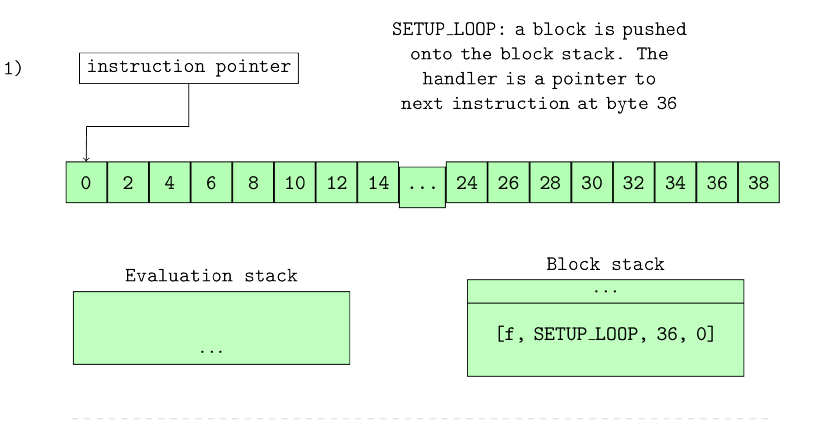
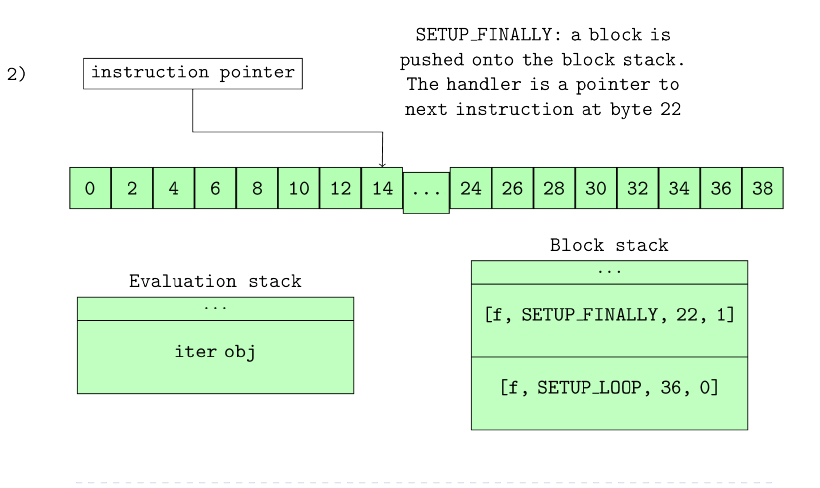
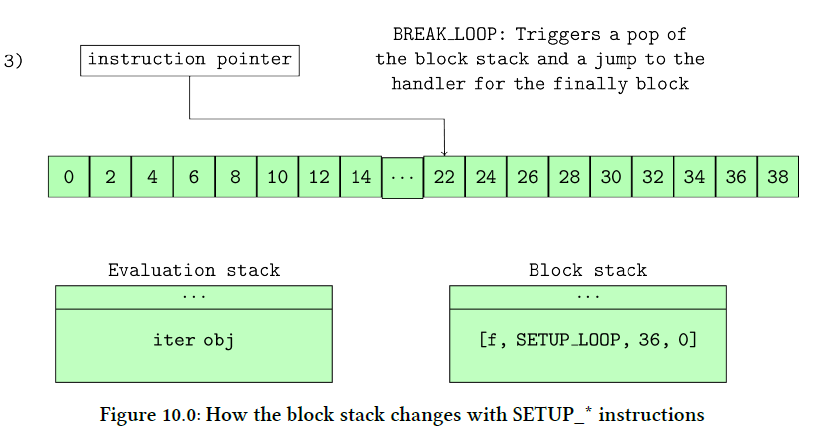
图 10.0 显示了块堆栈如何随每条指令的执行而变化。
在图 10.0 的第一个图中,SETUP_LOOP 操作码被执行,并将单个 SETUP_LOOP 块放置在块堆栈上。该块的处理程序是偏移量为 36 处的指令,因此当在正常执行下弹出堆栈时,解释器将跳转到该偏移量处并从此处继续执行。遇到 SETUP_FINALLY 操作码时,另一个块被压入块堆栈。我们可以看到,由于堆栈是后进先出数据结构,因此 finally 块将是最先出来,回顾一下,无论 break 语句如何,都必须执行 finally 。
使用块堆栈的真正地方是当在循环内的异常处理程序中遇到 break 语句时。当执行 BREAK_LOOP 操作码时,将 why 变量设置为 WHY_BREAK 并跳转到 fast_block_end 代码标签,如图 10.0 的第二张图所示,其中处理了块堆栈展开。展开只是在堆栈上弹出块并执行其处理程序的一个别名。因此,在这种情况下,SETUP_FINALLY 块从堆栈中弹出,并且解释器以字节码偏移量为 22 跳转到其处理程序。正常执行从该偏移量继续执行,直到遇到 END_FINALLY 语句为止。由于代码为何为 WHY_BREAK,因此将再次执行一次跳转到 fast_block_end 代码标签,在该标签处发生更多的堆栈展开操作:循环块保留在堆栈上。这次 (从图 10.0 中未显示),从堆栈弹出的块在字节偏移量为 36 处有一个处理程序,因此在该字节码偏移量处程序继续执行,从而完成循环退出并继续正常执行。
块堆栈的使用大大简化了虚拟机实现的实现。如果循环不是使用块堆栈实现的,则 BREAK_LOOP 之类的操作码将需要跳转目标。如果随后使用该 break 语句抛出一个 try..finally 结构,就会需要一个复杂的实现,在该实现中,我们必须跟踪 finally 块内的可选跳转目标,依此类推。
10.1 A Short Note on Exception Handling
有了对块堆栈的基本了解,就不难理解如何实现异常和异常处理。list 10.3 中的代码段试图向字符串添加数字。
Listing 10.3: Simple python function with exception handling
1 | def test1(): |
list 10.4 中显示了 list 10.3 中的简单函数生成的操作码。
Listing 10.4: Disassembly of function in listing 10.3
1 | 2 0 SETUP_EXCEPT 12 (to 14) |
鉴于前面的解释,我们应该对如果发生异常会如何执行此代码块有一个概念性的想法。总之,我们期望 Objects/abstract.c 模块中的 PyNumber_Add 函数为 BINARY_ADD 操作码返回 NULL 。这里需要说明的是,事实上函数除了返回 NULL 值之外,函数还在当前正在执行的线程的线程状态数据结构上设置异常值。回想一下,线程状态具有用于保存执行线程中当前异常的 curxc_type,curxc_value 和 curxc_traceback 字段;这些字段在展开异常搜索处理程序中的块堆栈时非常有用。你可以遵循从 Objects/abstract.c 模块中的 binop_type_error 函数一直到在当前执行线程上已设置值的同一模块中的 PyErr_Restore 函数的函数调用链。
在当前执行的线程上设置了异常值并且从函数调用返回了 NULL 值之后,解释器循环执行跳转到 error 标签,在该标签上不知道发生了什么。对于上面的示例,我们在块堆栈上只有一个块,即 SETUP_EXCEPT 块,其处理程序的字节码偏移量为 14 。一旦跳转到 error 处理程序标签,就可以开始展开堆栈。异常值的 traceback,异常值和异常类型会被推入值堆栈的顶部,SETUP_EXCEPT 处理程序从块堆栈中弹出,然后跳转到该处理程序,在这种情况下,程序从字节偏移为 14 的地方继续执行。现在观察 list 10.4 中从字节码偏移量为 16 到字节码偏移量为 20 的字节码:将 Exception 类加载到堆栈上,然后将其与引发并出现在堆栈上的异常进行比较。如果异常匹配,则正常执行可以继续,从值堆栈中弹出 exception 和 traceback ,并执行任意错误处理程序代码。如果没有异常匹配,则执行 END_FINALLY 指令,并且由于堆栈上仍存在异常,因此异常循环会中断。
在没有异常处理机制的情况下,用于测试功能的操作码更为直接,如清单10.5所示。
Listing 10.5: Disassembly of function in listing 10.3 when there is no exception handling
1 | 2 0 LOAD_CONST 1 (2) |
操作码不会在块堆栈上放置任何内容,因此,当发生异常并且跳转到 error 处理标签时,不会从堆栈上展开块,从而导致循环退出并存储错误。
这并未涵盖异常处理机制的全部的工作原理,但涵盖了 python 虚拟机中块堆栈与错误处理之间的交互作用的基本原理。还有一些其他的细节,例如在处理异常时引发异常的情况,嵌套异常处理程序和嵌套异常的情况等。
11. From Class code to bytecode
我们已经讨论了很多基础知识,讨论了 python 虚拟机或解释器如何执行代码的细节,但是对于像 Python 这样的面向对象的语言,我们实际上忽略了最重要的方法之一:用户定义的类如何精简为字节码并进行执行的基本内容。
通过对 Python 对象的讨论,我们对如何创建新的类有一个粗略的看法,但是直觉可能无法完全清晰的捕捉类创建的整个过程:从用户的定义到创建新类对象的实际字节码的过程;因此本章主要为了弥补这一点,并就此过程的发生方式进行阐述。
通常,我们会从一个非常简单的用户定义的类开始,如 lisitng 11.0 所示。
Listing 11.0: A simple class definition
1 | class Person: |
当将包含上述类定义的模块用 dis 模块进行反汇编时,将会输出如 list 11.1 中所示的字节码流。
Listing 11.1: A simple class definition
1 | 0 LOAD_BUILD_CLASS |
我们对字节 0 到字节 12 感兴趣,因为它们是创建新类对象并存储它的实际操作码,以便可以通过其名称 (在本例中为 Person) 进行引用。在这之前,我们在上面的操作码上进行扩展,然后看一下 Python 文档所指定的类创建过程。
文档中对过程的描述虽然非常高级,但是非常清楚。可以从 python 文档中推测出来,类创建的幕后过程大致涉及以下过程,但是没有特定的顺序。
- 类语句的主体被隔离到一个代码对象中。
- 确定用于类实例化的适当元类。
- 准备代表该类命名空间的类字典。
- 代表类主体的代码对象在此命名空间内执行。
- 创建类对象。
在最后一步中,通过实例化 type 类并传入类名称,基类和类字典作为参数来创建类对象。任何 prepare钩子都在实例化类对象之前运行。通过在类定义中提供 metaclass 关键字,可以显式指定在类对象创建中使用的元类。如果未提供,则类语句将会检查存在的基类元组中的第一个条目。如果没有使用基类,则搜索全局变量 metaclass,如果没有找到此值,Python 将使用默认的元类。
在随后的章节中将讨论有关元类的更多信息。整个类创建过程始于将 __build_class 函数加载到值堆栈上。该功能负责创建新类的所有繁重工作。为此,我们在编译阶段完成了上述创建过程的第一步。在此步骤中,代表类主体的代码对象通过偏移量为 2 的 LOAD_CONST 的指令加载到堆栈上。该代码对象由 MAKE_FUNCTION 操作码包装到函数对象中,并且很快就会明白为什么会发生这种情况。到那时,执行循环到达偏移量为 10 的地方,执行堆栈 (evaluation loop) 看起来会是类似于图 11.0 的结构。
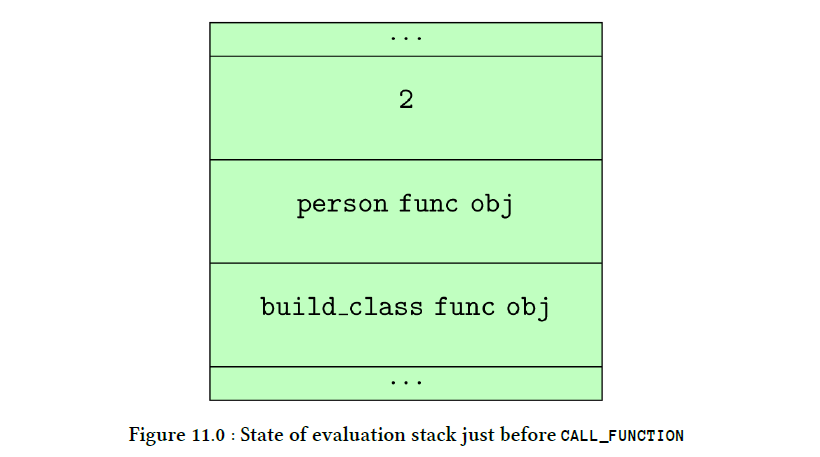
在偏移量为 10 的地方,CALL_FUNCTION 以其在执行堆栈 (evaluation loop) 上的值作为参数调用__build_class 函数。此函数在 Python/bltinmodule.c 模块中定义。该函数的主要部分专用于完整性检查:检查是否提供了正确的参数,它们是否具有正确的类型等。在进行这些完整性检查之后,该函数必须决定正确的元类。我们阐释了确定正确的元类的规则,正如 python 文档中所述。
- 如果没有给出基数并且没有给出显式元类,则使用 type();
- 如果给出了显式元类并且它不是 type() 的实例,则将其直接用作元类;
- 如果是 type() 的实例并且显示给出,或者定义了基类,那么使用派生程度最高的元类。
从派生的显式指定的元类 (如果有) 和所有指定的基类的元类 (即 type(cls)) 中选择派生最多的元类。最多的派生元类是所有这些候选元类的子类型。如果没有任何候选元类满足该条件,则该类定义将失败并显示 TypeError。
list 11.2 中显示了用于处理元类解析的 __build_class 函数的实际代码段,并对其进行了注释,以提供更加清晰的理解。
Listing 11.2: A simple class definition
1 | ... |
找到元类后,然后 __ build_class 继续检查元类上是否存在任何 prepare 属性;如果存在任何此类属性,则通过执行 prepare 钩子来传递类名,类基和类定义中的任何其他关键字参数,从而准备类命名空间。该钩子可用于自定义类行为。list 11.3 中的示例摘自元类定义和 python 文档使用示例,该示例显示了如何使用 prepare 钩子来实现具有属性顺序的类。
Listing 11.3: A simple meta-class definition
1 | class OrderedClass(type): |
如果在元类上没有定义 prepare 属性,则 build_class 函数将返回一个空的新字典,但是如果存在一个 __prepare 属性,则使用的命名空间是执行 prepare 属性的结果,如 list 11.4 所示。
Listing 11.4: Preparing for a new class
1 | ... |
在处理 prepare 钩子之后,现在该创建实际的类对象了。首先,在上一段创建的命名空间中执行类主体的代码对象。要理解为什么会这样,我们将对 list 11.5 中定义的类主体的代码对象进行反汇编。
Listing 11.5: Disassembly of code object for class body from listing 11.0
1 | 1 0 LOAD_NAME 0 (__name__) |
当执行此代码对象时,命名空间将包含类的所有属性,即类属性,方法等。然后,该命名空间将在过程的下一阶段用作对元类的函数调用的参数,如 list 11.6 所示。
Listing 11.6: Invoking a metaclass to create a new class instance
1 | // evaluate code object for body within namespace |
假设我们正在使用类型元类,则调用类型意味着在类的 tp_call 插槽 (slot) 中取消引用属性。然后, tp_call 函数反引用 tp_new 插槽 (slot) 中的属性,该属性实际创建并返回我们全新的类对象。然后将返回的 cls 值放回堆栈中,并存储到 Person 变量中。我们已经有了这个类和创建了一个新类的过程,而这实际上就是 Python 所具有的全部功能。
12. Generators: Behind the scenes.
生成器是 python 中真正美丽的概念之一。生成器函数是包含 yield 语句的函数,当调用生成器函数时,它将返回生成器。在 python 中,生成器的一种非常简单的用法是作为一个迭代器,它根据需要生成用于迭代的值。list 12.0 是生成器函数的一个非常简单的示例,该函数返回一个生成器,该生成器生成从 0 到 n 的值。
Listing 12.0: A simple generator
1 | def firstn(n): |
firstn 是一个生成器函数,因此用一个值调用 firstn 函数不会像常规函数那样返回简单的值,而是会返回生成器对象,该对象捕获计算的 continuation 。然后,我们可以使用 next 函数从返回的生成器对象或生成器对象的 send 方法获取连续值,以将值发送到生成器对象。在本章中,我们对生成器对象的语义以及生成器的使用方式或使用方式不感兴趣。我们的兴趣在于在 CPython 的幕后如何实现生成器。我们对如何暂停计算然后随后恢复这种计算感兴趣。我们来看一下这个概念背后的数据结构和思想,令人惊讶的是它们并不太复杂。首先,我们来看一个生成器对象的 C 实现。
12.1 The Generator object
生成器对象定义如 list 12.1 所示,通过该定义可以直观地了解如何暂停或恢复生成器执行。我们可以看到,生成器对象包含一个 frame 对象(从 frame 一章中调用执行 frame )和一个代码对象,这两个对象对于执行 python 字节码至关重要。
Listing 12.1: Generator object definition
1 | /* _PyGenObject_HEAD defines the initial segment of generator |
以下内容包含生成器对象的主要属性。
- prefix##_frame:此字段引用 frame 对象。该 frame 对象包含生成器的代码对象,并且在该 frame 内执行生成器对象的代码对象。
- prefix##_running:这是一个布尔值字段,指示生成器是否正在运行。
- prefix##_code:此字段引用与生成器关联的代码对象。这是在生成器运行时执行的代码对象。
- prefix##_name:这是生成器的名称,在list 12.0 中,值是 firstn。
- prefix##_qualname:这是生成器的标准名称。大多数情况下,此值与前缀##_name的值相同。
Creating generators
调用生成器函数时,生成器函数不会运行到完成状态并返回值,而是会返回生成器对象。这是可能的,因为在生成器函数的编译期间设置了 CO_GENERATOR 标志,并且该标志在代码对象执行之前发生的设置过程中非常有用。
在执行该函数的代码对象的过程中,调用 _PyEval_EvalCodeWithName 可以执行一些设置。作为设置过程的一部分,将执行功能代码对象的 CO_GENERATOR 标志的检查,并且在设置该标志而不是调用求值循环函数的情况下,将创建一个生成器对象并将其返回给调用者。魔术发生在 _PyEval_EvalCodeWithName 的最后一个代码块,如 list 12.2 所示。
Listing 12.2: _PyEval_EvalCodeWithName returns a generator object when processing a code object with generator flag
1 | /* Handle generator/coroutine/asynchronous generator */ |
从 list 12.2 中可以看到,生成器函数代码对象的字节码在调用生成器函数时从未执行,字节码仅在返回的生成器对象执行才会执行,我们接下来再看。
12.2 Running a generator
我们可以通过将生成器对象作为参数传递给下一个内置函数来运行它。这将导致生成器执行直到命中 yield 表达式,然后中止执行。这里对我们而言重要的问题是生成器如何能够捕获执行状态并随意更新执行状态。
从 list 12.1 回顾生成器对象定义,我们看到生成器有一个引用 frame 对象的字段,并且在创建生成器时 (如 list 12.2 所示) 将其填充。我们记得, frame 对象具有执行代码对象所需的所有状态,因此,通过引用该执行 frame ,生成器对象可以捕获其执行所需的所有状态。
现在我们知道了生成器对象是如何捕获执行状态的,接下来我们来解决如何恢复挂起的生成器对象的执行的问题,考虑到我们已经掌握的信息,这并不难解决。当使用生成器作为参数调用下一个内置函数时,下一个函数将取消引用生成器类型的 tp_iternext 字段,并调用该字段引用的任何函数。对于生成器对象,该字段引用一个函数 gen_iternext ,该函数简单地调用另一个函数 gen_send_ex,该函数执行恢复生成器对象执行的实际工作。回想一下,在创建生成器对象之前,所有初始化设置已由 _PyEval_EvalCodeWithName 函数执行,初始化了帧对象并正确初始化了变量,因此生成器对象的执行涉及到调用 PyEval_EvalFrameEx 并使用生成器中包含的帧对象
对象作为 frame 参数。然后,按照执行循环 (evaluation loop) 中有关章节的说明,执行 frame 中包含的代码对象的执行。
为了更深入地了解一个生成器函数,我们从 list 12.0 开始查看该生成器函数。从 list 12.0 中分解生成器功能将产生 list 12.3 中所示的一组字节码。
Listing 12.3: Disassembly of generator function from listing 12.0
1 | 4 0 LOAD_CONST 1 (0) |
当 list 12.3 中显示的生成器函数的字节码的执行到达字节偏移量 16 处的 YIELD_VALUE 操作码时,该操作码会导致执行 (evaluation) 挂起并将堆栈顶部的值返回给调用方。通过暂停,我们的意思是退出了当前正在执行的 frame 的执行循环 (evaluation loop) ,但是未释放该 frame ,因为它仍被生成器对象引用,因此当以该 frame 作为其参数之一调用 PyEval_EvalFrameEx 时, frame 可以再次继续执行。
Python 生成器不仅可以生成值,还可以使用生成器的 send 方法来使用值。这是可能的,因为 yield 是一个计算得出值的表达式。在带有值的生成器上调用 send 方法时,gen_send_ex 方法在调用执行 (evaluation) frame 对象之前将值放在生成器对象 frame 的执行堆栈 (evaluation stack) 上。在 list 12.3 中,紧随 YIELD_VALUE 指令的指令是 STORE_FAST,它将存储在堆栈顶部的任何值存储到赋值左侧的名称上。如果没有发送函数调用,则放在堆栈顶部的值是 “None” 。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章