原文地址:Let’s build a Full-Text Search engine
本文是一片关于搜索引擎文章的翻译,仅供个人学习使用。
全文搜索是人们每天都会使用但却没有意识到的工具之一。如果你用谷歌搜索 “golang coverage report” 或者想在电子商务网站找到 “indoor wireless camera” ,你就会用到某种全文搜索引擎。
全文搜索(Full-Text Search,FTS)是一个在一系列文档进行搜索特定内容的技术。这个文档可能是一个网页,报纸上的一篇文章,一个邮件信息,或者其他类型的内容。
这里我们会去构建一个我们自己的全文搜索引擎。在文章的最后,我们能够在数百万的文档中耗费1毫秒以内搜索到所需的内容。我们会以一个简单的搜索案例开始,例如:在所有文档中搜索带有cat的文档,然后我们会去扩展这个引擎去支持更加复杂的布尔查询。
注:最著名的FTS引擎叫Lucene(如Elasticsearch和solr就是建立在它之上的)。
Why FTS
在我们开始编写代码之前,你可能会问:我们能不能只用grep或者用循环进行检查每个文档,从而找到包含我们寻找内容的文档?答案是可以,但是这不是最好的方法。
Corpus
我们将搜索英语维基百科摘要的一部分。最新的dump位于dumps.wikimedia.org。截至今天,解压缩后的文件大小为913 MB。 XML文件包含超过60万个文档。
文档示例:
1 | <title>Wikipedia: Kit-Cat Klock</title> |
Loading documents
首先,我们需要从dump中中加载所有的文档,内置库encoding/xml处理起来非常方便:
1 | import ( |
每个加载的文档都会分配一个唯一的标识符。为简单起见,第一个加载的文档被分配的ID = 0,第二个ID = 1,依此类推。
First attempt
Searching the content
现在我们把所有的文档都加载到内存里了,我们可以尝试在当中找到有关与cat的文档。最开始,尝试循环所有文档并检查它们中间是否包含cat:
Now that we have all documents loaded into memory, we can try to find the ones about cats. At first, let’s loop through all documents and check if they contain the substring cat:
1 | func search(docs []document, term string) []document { |
在我的笔记本中,这个查询花费了103ms,不算太差。如果从输出中检查部分文档,你可能会注意到该函数匹配到了 caterpillar 和 category ,但与 Cat 的大写字母 C 不匹配,那不是我想要的。
我们需要在更进一步之前修复两个问题:
- 让搜索大小写不敏感(这样就能搜索到Cat了);
- 匹配一个单词,而不是子字符串(这样 caterpillar 和communication就不会被匹配到了)。
Searching with regular expressions
很快想到的并且易实现的一个解决方法是使用正则表达式: (?i)\bcat\b,
(?i)让表达式大小写不敏感;\b匹配一个单词边界;
1 | func search(docs []document, term string) []document { |
整个查找的过程耗时超过2秒。如你所见,尽管只有60万个文档,查找也开始变慢。尽管该方法易于实施,但伸缩性不好。随着数据集变得越来越大,我们需要扫描越来越多的文档。该算法的时间复杂度是线性的,需要扫描的文档数等于文档总数。如果我们有600万个文档而不是60万个文档,则搜索将花费20秒。因此,我们需要更好的方法。
Inverted Index
为了让查找更快,我们将对文本进行预处理并预先建立索引。
FTS的核心是一个称为倒排索引的数据结构。倒排索引将文档中的每个单词与包含该单词的文档相关联。
例如:
1 | documents = { |
Below is a real-world example of the Inverted Index. An index in a book where a term references a page number:
以下是倒排索引的真实示例。一本书的索引及其中术语引用页码:

Text analysis
在我们开始建索引之前,我们需要将源文档拆分成一系列的单词(词项,token),从而适合索引和搜索。文本分析器(text analyzer)由一个标记器(tokenizer)和多个过滤器(filter)组成。
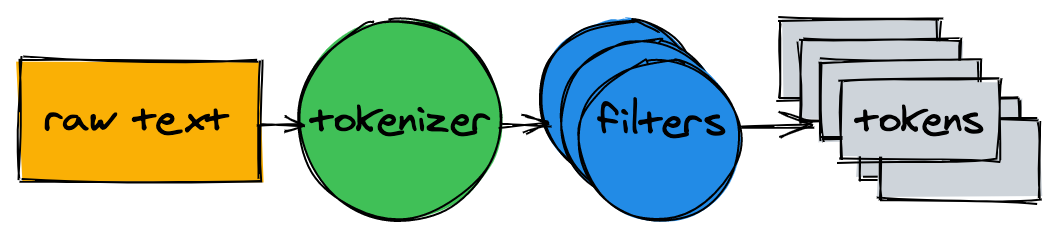
Tokenizer
文本分析的第一步是标记。它的工作是将文本转化为一系列token。我们的实现是在单词边界上分割文本并删除标点符号:
1 | func tokenize(text string) []string { |
Filters
在大多数情况下,仅将文本转换为token列表是不够的。为了使文本更易于索引和搜索,我们需要进行其他标准化。
Lowercase
为了使搜索不区分大小写,小写过滤器将标记转换为小写。 cAt,Cat 和 caT 被标准化为 cat。稍后,当我们查询索引时,我们也将小写搜索词。这将使搜索词cAt 与文本 Cat 相匹配。
1 | func lowercaseFilter(tokens []string) []string { |
Dropping common words
几乎所有英文文本都包含常用单词,例如a,I,the或be。这些单词称为停用词。我们将删除它们,因为几乎所有文档都将与停用词匹配。
没有停用词的“官方”列表。让我们按OEC排名排除前十名。随时添加更多:
1 | var stopwords = map[string]struct{}{ // I wish Go had built-in sets. |
Stemming
由于语法规则,文档可能包含同一单词的不同形式。词干将单词还原为基本形式。例如,fishing,fished和fisher可以简化为基本形式(词干)fish。
实施词干分析器是一项艰巨的任务,本文不做介绍。我们将采用已有的模块之一:
1 | import snowballeng "github.com/kljensen/snowball/english" |
注:词根并非总是有效的词。例如,某些词干可以将airline减少为airlin。
Putting the analyzer together
1 | func analyze(text string) []string { |
标记器和过滤器将句子转换为token列表:
1 | > analyze("A donut on a glass plate. Only the donuts.") |
tokens 已准备好建立索引。
Building the index
Back to the inverted index. It maps every word in documents to document IDs. The built-in map is a good candidate for storing the mapping. The key in the map is a token (string) and the value is a list of document IDs:
回到倒排索引,它将文档中的每个单词映射到文档ID。内置map是存储映射的理想选择。映射中的键是token(字符串),值是文档ID的列表:
1 | type index map[string][]int |
构建索引包括分析文档并将其ID添加到map:
1 | func (idx index) add(docs []document) { |
映射中的每个token都引用包含token的文档的ID:
1 | map[donut:[1 2] glass:[1] is:[2] on:[1] only:[1] plate:[1]] |
Querying
要查询索引,我们将应用与索引相同的标记器和过滤器:
1 | func (idx index) search(text string) [][]int { |
最后,我们可以找到所有提及cat的文件。搜索60万文档不到一毫秒(18µs)!
使用倒排索引,搜索查询的时间复杂度与搜索token的数量呈线性关系。在上面的示例查询中,除了分析输入文本外,搜索仅需要执行三次map查找。
Boolean queries
上一节中的查询为每个token返回了一份文档列表。我们通常希望在搜索框中输入small wild cat时找到的结果列表是同时包含small,wild和cat的结果。下一步是计算列表之间的交集。这样,我们将获得与所有标记匹配的文档列表。
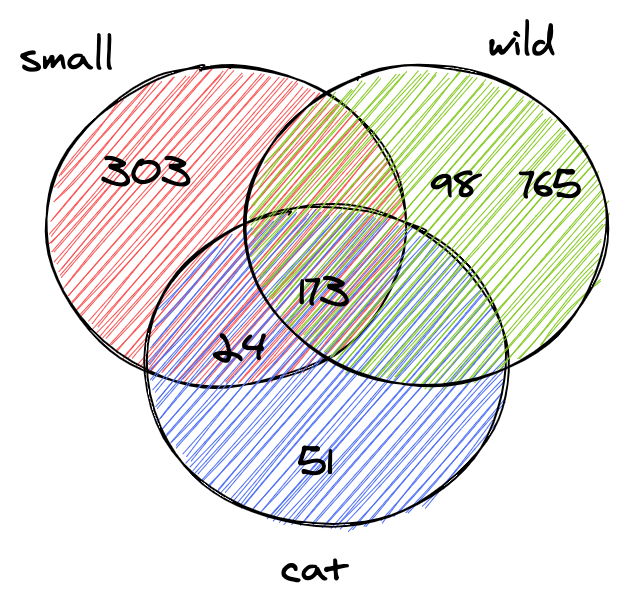
幸运的是,倒排索引中的ID按升序插入。由于ID已排序,因此可以在线性时间内计算两个列表之间的交集。相交函数同时迭代两个列表,并收集两个列表中都存在的ID:
1 | func intersection(a []int, b []int) []int { |
更新后的搜索将分析给定的查询文本,查找令牌并计算ID列表之间的交集:
1 | func (idx index) search(text string) []int { |
Wikipedia转储仅包含两个同时匹配small,wild和cat的文档:
1 | > idx.search("Small wild cat") |
Conclusions
我们刚刚构建了全文搜索引擎。尽管它很简单,但它可以为更高级的项目打下坚实的基础。
我没有涉及很多可以显着提高性能并使引擎更友好的东西。以下是一些进一步改进的想法:
扩展布尔查询以支持OR和NOT。
将索引存储在磁盘上:
- 每次重新启动应用程序时重建索引可能需要一段时间。
- 大索引可能无法容纳在内存中。
试用内存和CPU效率高的数据格式来存储文档ID集。Roaring Bitmaps。
支持索引多个文档字段。
按相关性对结果进行排序。
完整的源代码可在GitHub上找到。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章